本文为摘录,原文为: attachments/pdf/6/willhalm-vldb2009.pdf
现代服务器上的巨大系统内存可用性引起了对主内存数据库引擎的热情。数据仓库系统中,高度压缩的列式数据结构很突出。
为了跟踪数据量和系统负载,许多系统采用高度分布式的无共享方式。所有系统的基本原则是对一个或多个压缩列进行全表扫描。最近的 研究提出了不同的技术以加快表扫描速度,如智能压缩、使用额外的硬件如图形卡或 FPGA。
本文展示了利用标准超标量处理器中的嵌入式向量处理单元(VPUs)可以将主内存全表扫描性能提高数倍。
这一结果实现了不改变硬件架构,因此不增加额外功耗。此外,由于片上 VPUs 直接访问系统的 RAM,标准主内存数据库引擎在使用新的 SIMD-扫描方法时无需额外昂贵的拷贝操作。因此, 我们建议将该扫描方法用作列式主内存存储的标准扫描操作符
1 Introduction
为了节省内存并提高访问速度,内存数据结构会被高度压缩。 这是通过使用不同变种的轻量级压缩(LWC)技术实现的,例如游程编码或多版本固定长度编码。
越来越复杂的压缩算法被使用,全表扫描操作从 I/O 限制转变为 CPU 限制。
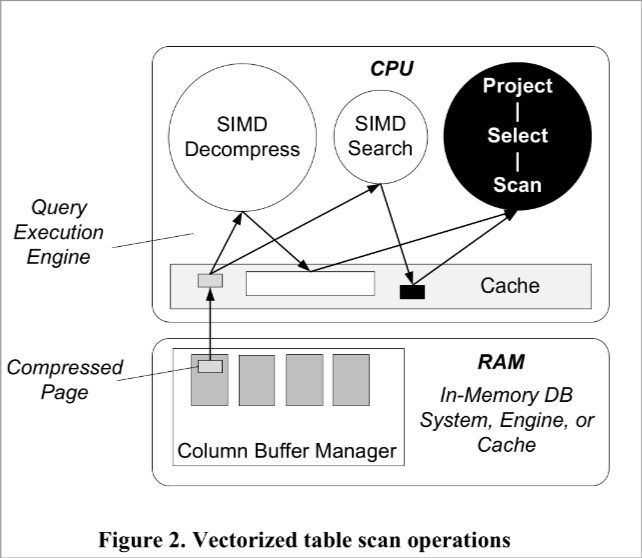
Vectorized Value Decompression:
- introduce a fast SIMD decompression approach for LWC Numebr Compression (LWC-NC)
Vectorized Predicate Handling
- We present a new concept and implementation of SIMD predicate search.