- 1 Introduction
- 2 Related Work
- 2.1 Storage Layouts
- 2.2 Bit-(Un)Packing
- 3 SIMD-Friendly Bit-(Un)Packing
- 4 Composable Functions
- 5 Composable Compression Schemes
本文为摘录,原文为: attachments/pdf/a/Towards a New File Format for Big Data - SIMD-Friendly Composable Compression (2020-AzimAfroozeh).pdf
1 Introduction
2 Related Work
2.1 Storage Layouts
2.1.1 NSM
传统上,在数据库系统中,表格数据通常按照磁盘页的起始行逐行存储。这种存储方式被称为 N-ary 存储模型(NSM)。如图 2.1 所示,如果元组大小是可变的,NSM 可能会在页面末尾使用偏移表来定 位每个元组的起始位置。此外,每个元组都以元组头(RH)开头,包含有关元组的信息。RH 以空位图 开头,用于支持空值;以偏移量开头,用于支持可变属性的变量长度值;以及其他实现特定的细节, 以使布局更加灵活。

2.1.2 DSM
这段文字介绍了分解存储模型(DSM)和它与非分解存储模型(NSM)的比较。DSM 将数据按列存储, 只提供需要的属性。与 NSM 相比,DSM 提供更高效的缓存利用,因为属性值聚集在一起。此外,由于相 邻元组的相似性,DSM 相比 NSM 提供更多的压缩机会。
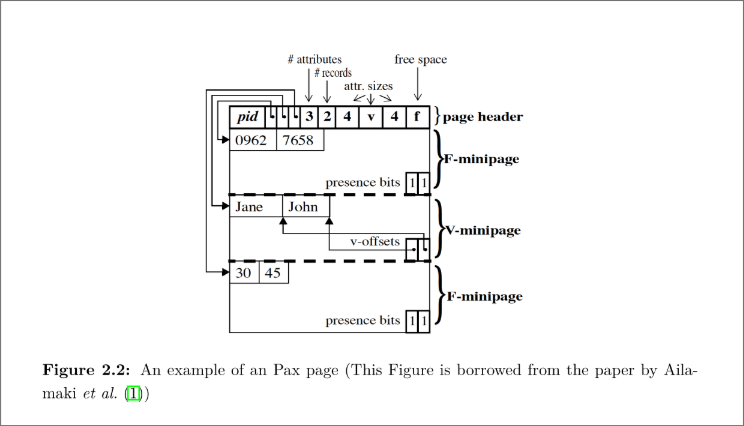
2.1.3 PAX
这段文字介绍了在处理在线分析处理(OLAP)工作负载时,DSM 是更好的模型。但是,如果需要重构 整个元组,DSM 会产生性能开销,因为需要在运行时显式地进行元组重构。Ailamaki 等人提出了“跨分 区属性”(PAX)技术,该技术结合了 DSM 的元组间空间局部性和 NSM 的低元组重构成本。PAX 将元组的 所有属性存储在同一个页面中。但是,在页面内,PAX 按列存储所有属性。
2.2 Bit-(Un)Packing
32 位系统架构中,整数通常使用 32 位存储,尽管可能可以使用更少的位来存储它们。例如,具有
值为 70(0b1000110)的 32 位整数可以使用 7 位而不是 32 位进行存储。一般来说,在[0,2b]范
围内的整数可以使用 b 位编码并连接成一个单独的位字符串。这个过程被称为 位填充
(bit-packing) 。反向操作,即将位字符串转换回可由机器寻址的整数数组的操作被称为 位取消填 充 , bit-unpacking 。位取消填充可以使用五个简单的操作(加载、移位、与、或和存储)来提取
每个整数,如图 2.3 所示。
在将 32 位数据加载到 CPU 寄存器中之后,使用右移操作将期望的位放置到寄存器的开头。此外,使用 预定义的掩码寄存器进行按位 AND 操作(用 0 表示随机位,用 1 表示期望的位),可以将具有任意值的 位更改为 0。这种实现效率高,因为它不涉及任何分支。

- Bit Alignment:
2.2.1 Vectorized Bit-Unpacking
Willhaml 等提出了一个方法来通过 SIMD 来批量 bitunpack:
16-Byte Alignment: 通过 128 位的 SIMD aligned load 从内存中加载 128-bit 的数据 使用一个 128 位的 SIMD 对齐加载指令从内存中加载 128 位的数据。对于一些位宽值,比如 9, 第一个整数值可能不完全加载,因为它跨越了两个 128 位的寄存器。为了处理这些情况,作者更 喜欢使用一个 128 位 SIMD 寄存器串联指令,而不是 128 位 SIMD 不对齐加载指令,因为 SIMD 不对齐的指令在旧处理器上的计算成本高昂。
4-Byte Alignment: four compressed integer values are copied to four separate 32-bit lanes in a new register using a SIMD shuffle mask instruction.
使用 SIMD 洗牌掩码指令将四个压缩整数值复制到新寄存器中的四个独立的 32 位通道。
Bit Alignment: 通过将每个语段任意移动几次,通过 SIMD 乘以四个不同整数和一个 SIMD 右移 指令将最后一个寄存器中的四个整数的每个语段的第一位对齐。
然而,Willhalm 等人的方法仅适用于 SSE,无法扩展到 AVX2,因为 Shuffle 指令无法跨所有 lane 移动字节。
Polychroniou 等人提出了一项更改,以调整 Willhalm 等人的方法以适用于 AVX2(33)。 为了模拟 256 位跨 lane Shuffle,我们可以将寄存器的每个半段(128 位)复制到两个半段,并使用常规的 256 位 Shuffle。 此外,Willhalm 等人将他们的位解压实现翻译为英特尔 AVX2 指令(34)。 在 Willhalm 的新实现中,模拟的移位操作被 AVX2 矢量-矢量移位指令所取代。 此外,与他们之前的实现相反,新的实现使用非对齐加载指令而不是对齐加载指令,因为他们声称对于当前架构, 这个指令比对齐加载指令更快。只有在数据加载分裂跨越缓存线时才会有性能损失,这被其他情况下的减少所分摊。
除了水平布局(即连续存储元组)外,Schlegel 等人提出了一种称为垂直布局的替代布局(2)。在 k-垂直布局中,k个连续的位压缩元组存储在不同的存储字中。
图 2.4 显示了一个 4 路垂直布局的示例,其中每个数字表示序列中整数的位置。可以看到,每 4 个连续整数分布在 4 个不同的字中。垂直布局使我们能够使用单个加载/存储 SIMD 指令加载/存储 压缩数据,而无需使用置换指令将元组分配到 SIMD lane 中。Lemire 等人使用 4 路垂直布局使用 相同的位宽位压缩 128 个元组,以利用 SSE SIMD 指令(35)。
3 SIMD-Friendly Bit-(Un)Packing
In this chapter we present our 1024-bit interleaved bit-(un)packing technique. As discussed in Section 2.2.1, the most efficient Bit-(un)packing approach is proposed by Lemire et al. (35), which uses a 4-way vertical layout.
在本章中,我们介绍了我们的 1024 位交错位(非)打包技术。正如第 2.2.1 节 所讨论的那样,Lemire 等人(35)提出了最有效的位(非)打包方法,采用 4 路垂直布局。