- 1 Introduction
- 1.1 Virtual IDs
- 1.2 Block-oriented and vectorized processing \\
- 1.3 Late materialization 晚期物化
- 1.4 Column-specific compression
- 1.5 Direct operation on compressed data
- 1.6 Efficient join implementations
- 1.7 Redundant representation of individual columns in dif- ferent sort orders
- 1.8 Database cracking and adaptive indexing
- 1.9 Efficient loading architectures
- 2 Column-store internals and advanced techniques
本文为摘录,原文为: attachments/pdf/d/The Design and Implementation of Modern Column-Oriented Database Systems (abadi-column-stores).pdf
1 Introduction
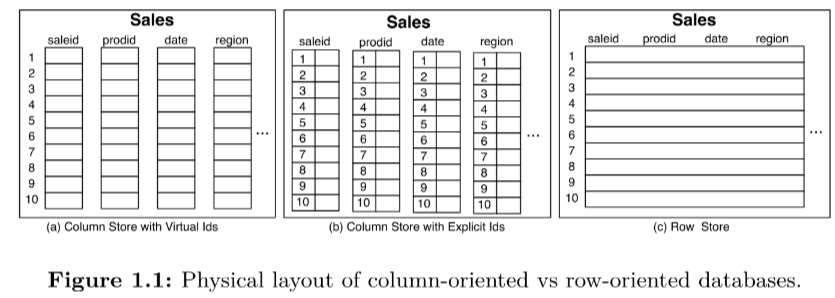
1.1 Virtual IDs
通过固定大小来存储数据,省掉存储 ID 的开销
1.2 Block-oriented and vectorized processing \\
- CPU 效率和 Cache 使用率更高
- 算子间传递多个 tuple 组成的 block
- 每个 block 大小为 cache size 大小
- 每个 block 中一般包含多个记录
- 自动向量化(编译器 + CPU)
1.3 Late materialization 晚期物化
- 延迟将多列 join 成宽表的时机
1.4 Column-specific compression
1.5 Direct operation on compressed data
尽量让数据以压缩方式存储在内存中,对其进行操作,直到必需的时候再解压给外层。
1.6 Efficient join implementations
1.7 Redundant representation of individual columns in dif- ferent sort orders
1.8 Database cracking and adaptive indexing
1.9 Efficient loading architectures
2 Column-store internals and advanced techniques
2.1 Vectorized Processing 向量化处理
2.2 Compression
2.2.1 Run-length Encoding
2.2.2 Bit-Vector Encoding
2.2.3 Dictionary
2.2.4 Frame Of Reference (FOR)
2.2.5 The Patching Technique
2.3 Operating Directly on Compressed Data 压缩态计算
- This benefit is magnified for compression schemes like run length encoding that combine multiple values within a column inside a single compression symbol.
- Operating directly on compressed data requires modifica- tions to the query execution engine.