- 1 Shared-Storage 带来的挑战
- 2 架构原理
- 3 数据一致性
- 4 低延迟复制
- 4.1 传统流复制的问题
- 4.2 优化 1:只复制 Meta
- 4.3 优化 2:页面回放优化
- 4.4 优化 3:DDL 锁回放优化
- 5 Recovery 优化
- 5.1 背景
- 5.2 Lazy Recovery
- 5.3 Persistent BufferPool
1 Shared-Storage 带来的挑战
基于 Shared-Storage,数据库由传统的 share nothing,转变成了 Shared-Storage 架构。需要解决以 下问题:
- 数据一致性:由原来的 N 份计算+N 份存储,转变成了 N 份计算+1 份存储。
- 读写分离:如何基于新架构做到低延迟的复制。
- 高可用:如何 Recovery 和 Failover。
- IO 模型:如何从 Buffer-IO 向 Direct-IO 优化。
2 架构原理
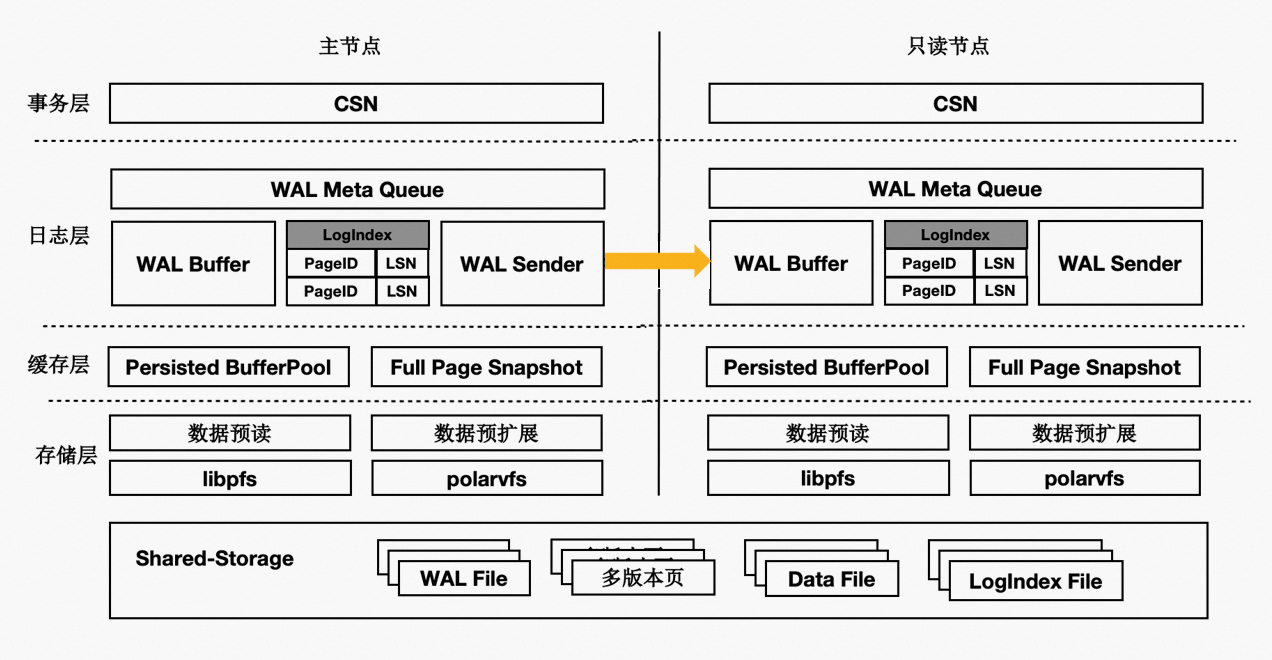
基于 Shared-Storage 的 PolarDB PostgreSQL 版的架构原理如下:
主节点为可读可写节点(RW),只读节点为只读(RO)。
Shared-Storage 层,只有主节点能写入,因此主节点和只读节点能看到一致的落盘的数据。
只读节点的内存状态是通过回放 WAL 保持和主节点同步的。
主节点的 WAL 日志写到 Shared-Storage,仅复制 WAL 的 meta 给只读节点。
只读节点从 Shared-Storage 上读取 WAL 并回放。
3 数据一致性
3.1 传统数据库的内存状态同步
传统 share nothing 的数据库,主节点和只读节点都有各自的内存和存储,只需要从主节点复制 WAL 日志到只读节点,并在只读节点上依次回放日志即可,这也是复制状态机的基本原理。
3.2 基于 Shared-Storage 的内存状态同步
存储计算分离后,Shared-Storage 上读取到的页面是一致的,内存状态是通过从 Shared-Storage 上 读取最新的 WAL 并回放得来,如下图所示:

主节点通过刷脏将版本 200 写入到 Shared-Storage。
只读节点基于版本 100,并回放日志得到 200。
3.3 基于 Shared-Storage 的过去页面
上述流程中,只读节点中基于日志回放出来的页面会被淘汰掉,此后需要再次从存储上读取页面, 会出现读取的页面是之前的老页面,称为过去页面。如下图所示:
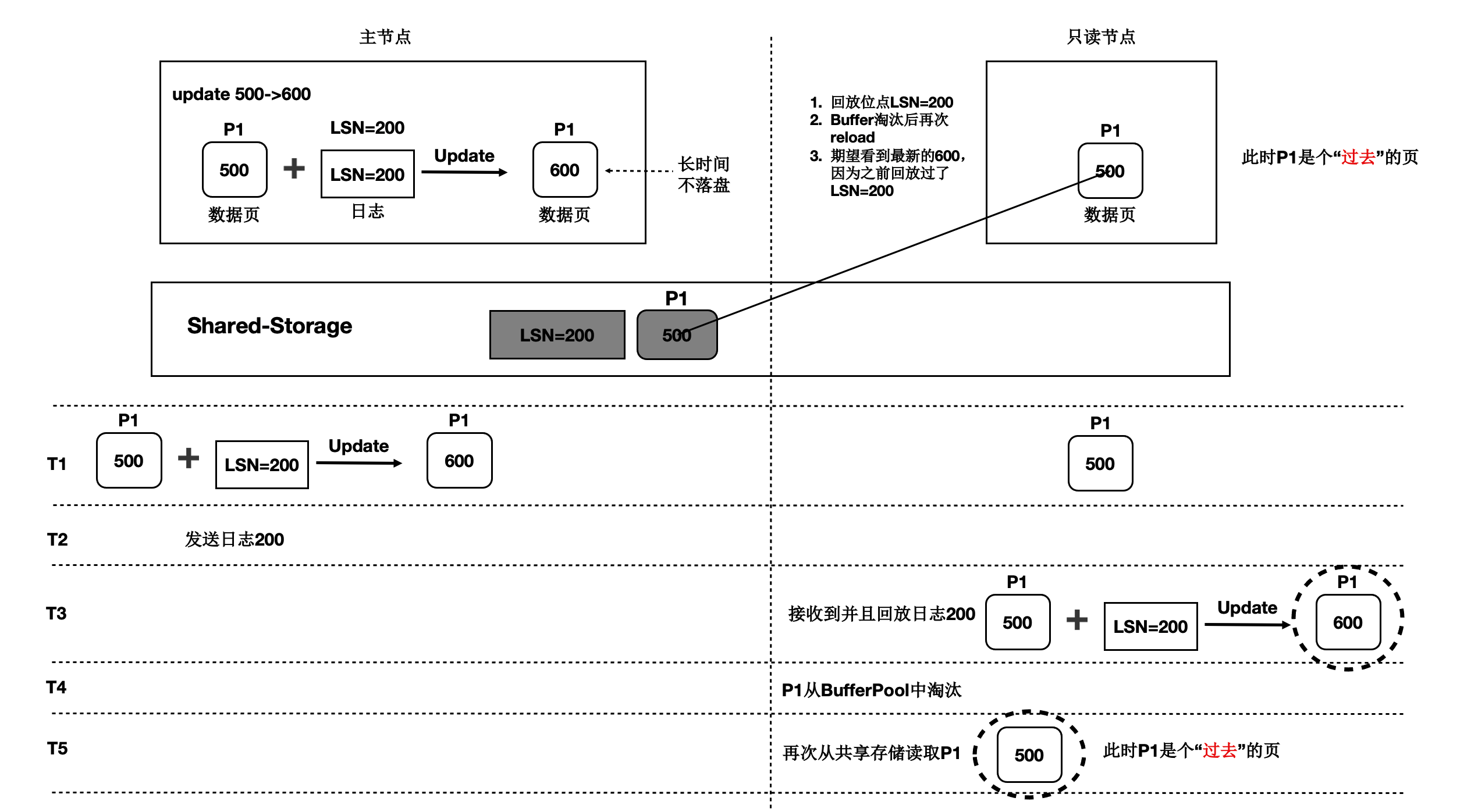
T1 时刻,主节点在 T1 时刻写入日志 LSN=200,把页面 P1 的内容从 500 更新到 600。
只读节点此时页面 P1 的内容是 500。
T2 时刻,主节点将日志 200 的 meta 信息发送给只读节点,只读节点得知存在新的日志。
T3 时刻,此时在只读节点上读取页面 P1,需要读取页面 P1 和 LSN=200 的日志,进行一次回放,得 到 P1 的最新内容为 600。
T4 时刻,只读节点上由于 BufferPool 不足,将回放出来的最新页面 P1 淘汰掉。
主节点没有将最新的页面 P1 为 600 的最新内容刷脏到 Shared-Storage 上。
T5 时刻,再次从只读节点上发起读取 P1 操作,由于内存中已经将 P1 淘汰掉了,因此从 Shared-Storage 上读取,此时读取到了过去页面的内容。
3.4 过去页面的解法
只读节点在任意时刻读取页面时,需要找到对应的 Base 页面和对应起点的日志,依次回放。如下图 所示:
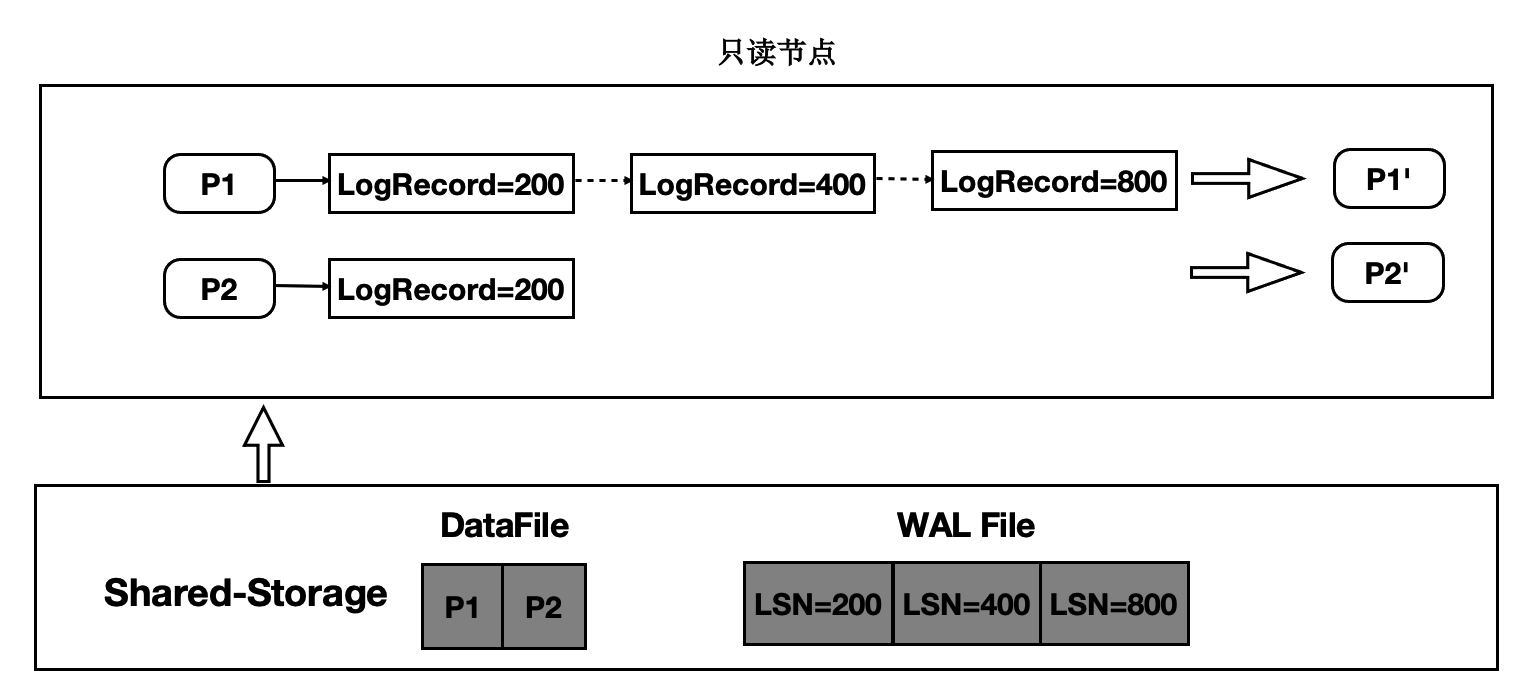
在只读节点内存中维护每个 Page 对应的日志 meta。
在读取时一个 Page 时,按需逐个应用日志直到期望的 Page 版本。
应用日志时,通过日志的 meta 从 Shared-Storage 上读取。
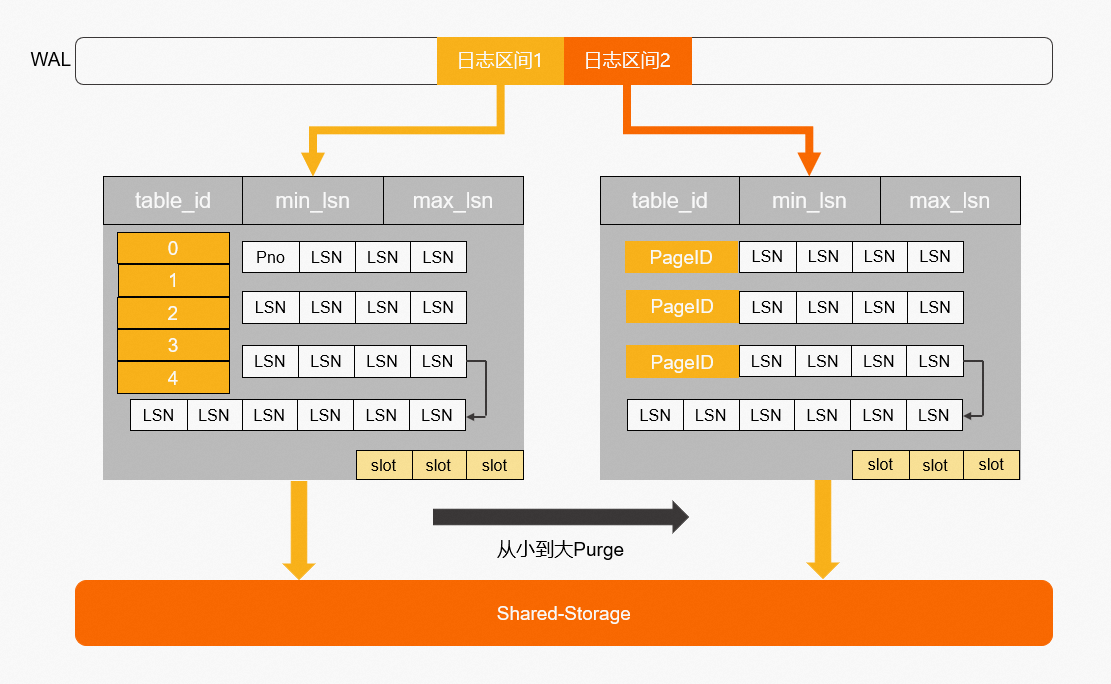
通过上述分析,需要维护每个 Page 到日志的倒排索引,而只读节点的内存是有限的,因此这个 Page 到日志的索引需要持久化,PolarDB PostgreSQL 版设计了一个可持久化的索引结构-LogIndex。 LogIndex 本质是一个可持久化的 hash 数据结构。
只读节点通过 WAL receiver 接收从主节点过来的 WAL meta 信息。
WAL meta 记录该条日志修改了哪些 Page。
将该条 WAL meta 插入到 LogIndex 中。其中,key 是 Page ID,value 是 LSN。
一条 WAL 日志可能更新了多个 Page(索引分裂),在 LogIndex 中有多条记录。
同时在 BufferPool 中给该 Page 打上 outdate 标记,以便下次读取的时候从 LogIndex 重回放对应的 日志。
当内存达到一定阈值时,LogIndex 异步将内存中的 hash 刷到盘上。
通过 LogIndex 解决了刷脏依赖过去页面的问题,也是将只读节点的回放转变成了 Lazy 的回放:只需 要回放日志的 meta 信息即可。
3.5 基于 Shared-Storage 的未来页面
在存储计算分离后,刷脏依赖还存在未来页面的问题。如下图所示:
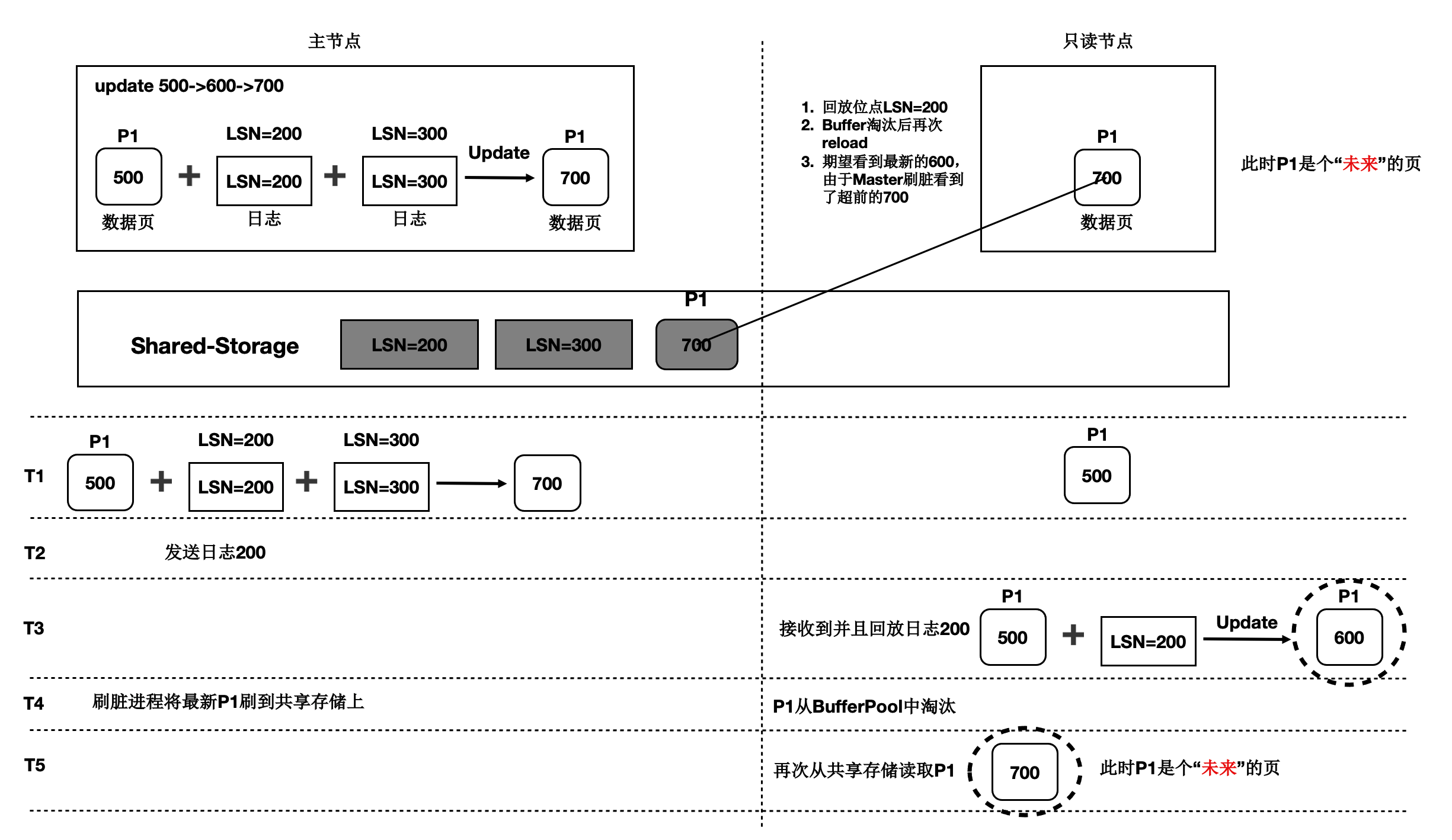
T1 时刻,主节点对 P1 更新了 2 次,产生了 2 条日志,此时主节点和只读节点上页面 P1 的内容都是 500。
T2 时刻, 发送日志 LSN=200 给只读节点。
T3 时刻,只读节点回放 LSN=200 的日志,得到 P1 的内容为 600,此时只读节点日志回放到了 200, 后面的 LSN=300 的日志对其来说还不存在。
T4 时刻,主节点刷脏,将 P1 最新的内容 700 刷到了 Shared-Storage 上,同时只读节点上 BufferPool 淘汰掉了页面 P1。
T5 时刻,只读节点再次读取页面 P1,由于 BufferPool 中不存在 P1,因此从共享内存上读取了最新 的 P1,但是只读节点并没有回放 LSN=300 的日志,读取到了一个对其来说超前的未来页面。
未来页面的问题是:部分页面是未来页面,部分页面是正常的页面,会导致数据不一致。例如, 索引分裂成 2 个 Page 后,一个读取到了正常的 Page,另一个读取到了未来页面,B+Tree 的索引结 构会被破坏。
3.6 未来页面的解法
未来页面的原因是主节点刷脏的速度超过了任一只读节点的回放速度(虽然只读节点的 Lazy 回放已 经很快了)。因此,解法就是对主节点刷脏进度时做控制:不能超过最慢的只读节点的回放位点。 如下图所示:
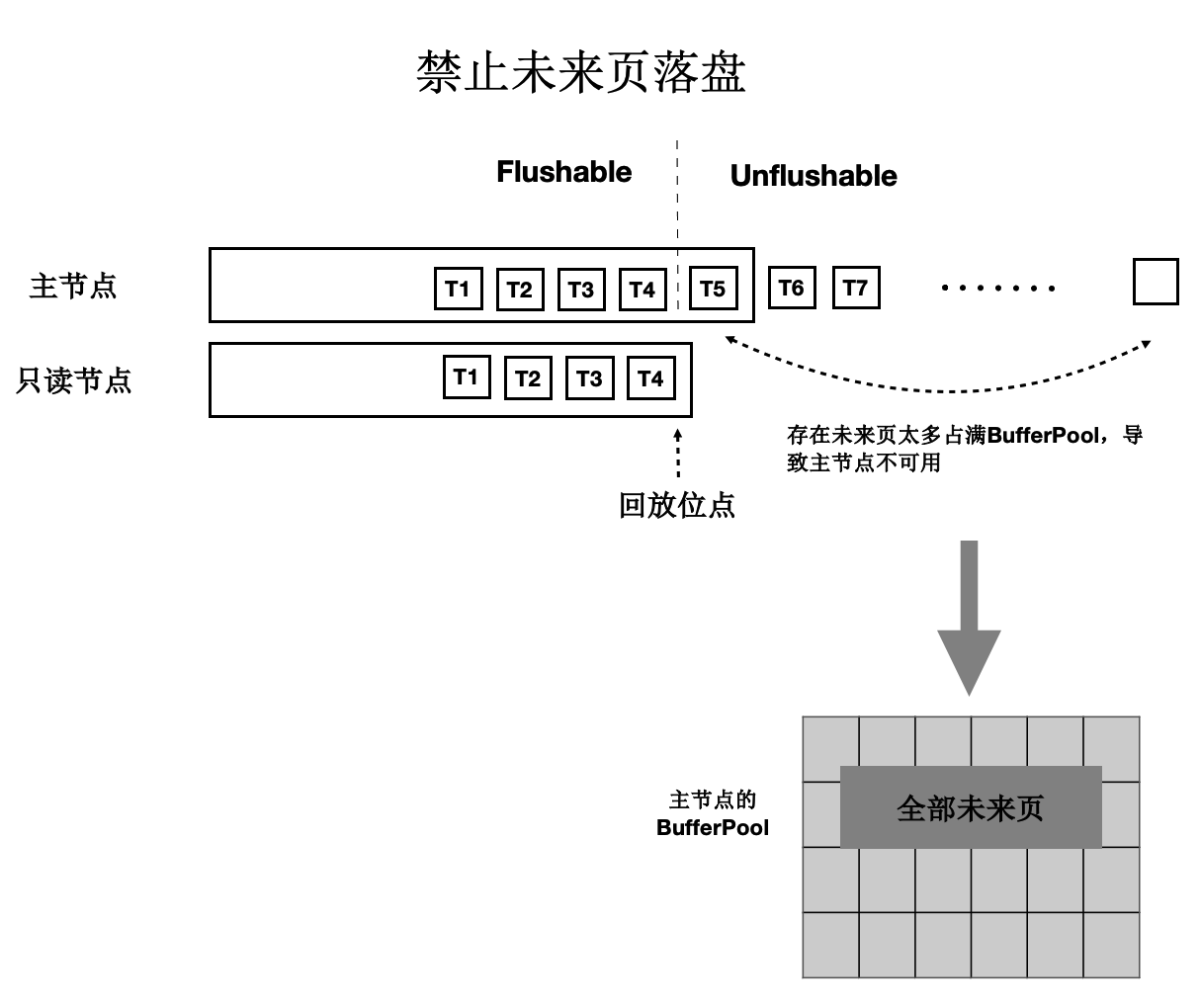
只读节点回放到 T4 位点。
主节点在刷脏时,对所有脏页按照 LSN 排序,仅刷在 T4 之前的脏页(包括 T4),之后的脏页不刷。
其中,T4 的 LSN 位点称为一致性位点。
4 低延迟复制
4.1 传统流复制的问题
同步链路:日志同步路径 IO 多,网络传输量大。
页面回放:读取和 Buffer 修改慢(IO 密集型+CPU 密集型)。
DDL 回放:修改文件时需要对修改的文件加锁,而加锁的过程容易被阻塞,导致 DDL 慢。
快照更新:RO 高并发引起事务快照更新慢。

流程如下:
主节点写入 WAL 日志到本地文件系统中。
WAL Sender 进程读取,并发送。
只读节点的 WAL Receiver 进程接收写入到本地文件系统中。
回放进程读取 WAL 日志,读取对应的 Page 到 BufferPool 中,并在内存中回放。
主节点刷脏页到 Shared Storage。
从上述流程可以看到,整个链路是很长的,只读节点延迟高,影响用户业务读写分离负载均衡。
4.2 优化 1:只复制 Meta
因为底层是 Shared-Storage,只读节点可直接从 Shared-Storage 上读取所需要的 WAL 数据。因此主节 点只把 WAL 日志的元数据(去掉 Payload)复制到只读节点,这样网络传输量小,减少关键路径上的 IO。如下图所示:
WAL Record 是由:Header,PageID,Payload 组成。
由于只读节点可以直接读取 Shared-Storage 上的 WAL 文件,因此主节点只把 WAL 日志的元数据发送 (复制)到只读节点,包括:Header,PageID。
在只读节点上,通过 WAL 的元数据直接读取 Shared-Storage 上完整的 WAL 文件。
通过上述优化,能显著减少主节点和只读节点间的网络传输量。从下图可以看到网络传输量减少了 98%。
4.3 优化 2:页面回放优化
在传统数据库中日志回放的过程中会读取大量的 Page 并逐个日志 Apply,然后落盘。该流程在用户读 IO 的关键路径上,借助存储计算分离可以做到:如果只读节点上 Page 不在 BufferPool 中,不产生任 何 IO,仅仅记录 LogIndex 即可。
可以将回放进程中的以下 IO 操作 offload 到 session 进程中:
数据页 IO 开销。
日志 apply 开销。
基于 LogIndex 页面的多版本回放。
如下图所示,在只读节点上的回放进程中,在 Apply 一条 WAL 的 meta 时:

如果对应 Page 不在内存中,仅仅记录 LogIndex。
如果对应的 Page 在内存中,则标记为 Outdate,并记录 LogIndex,回放过程完成。
用户 session 进程在读取 Page 时,读取正确的 Page 到 BufferPool 中,并通过 LogIndex 来回放相应的 日志。
可以看到,主要的 IO 操作由原来的单个回放进程 offload 到了多个用户进程。
通过上述优化,能显著减少回放的延迟,比其他云原生数据库快 30 倍。
4.4 优化 3:DDL 锁回放优化
在主节点执行 DDL 时(例如,drop table),需要在所有节点上都对表上排他锁,这样能保证表文件 不会在只读节点上读取时被主节点删除掉了(因为文件在 Shared-Storage 上只有一份)。在所有只 读节点上对表上排他锁是通过 WAL 复制到所有的只读节点,只读节点回放 DDL 锁来完成。而回放进程 在回放 DDL 锁时,对表上锁可能会阻塞很久,因此可以通过把 DDL 锁 offload 到其他进程上来优化回放 进程的关键路径。
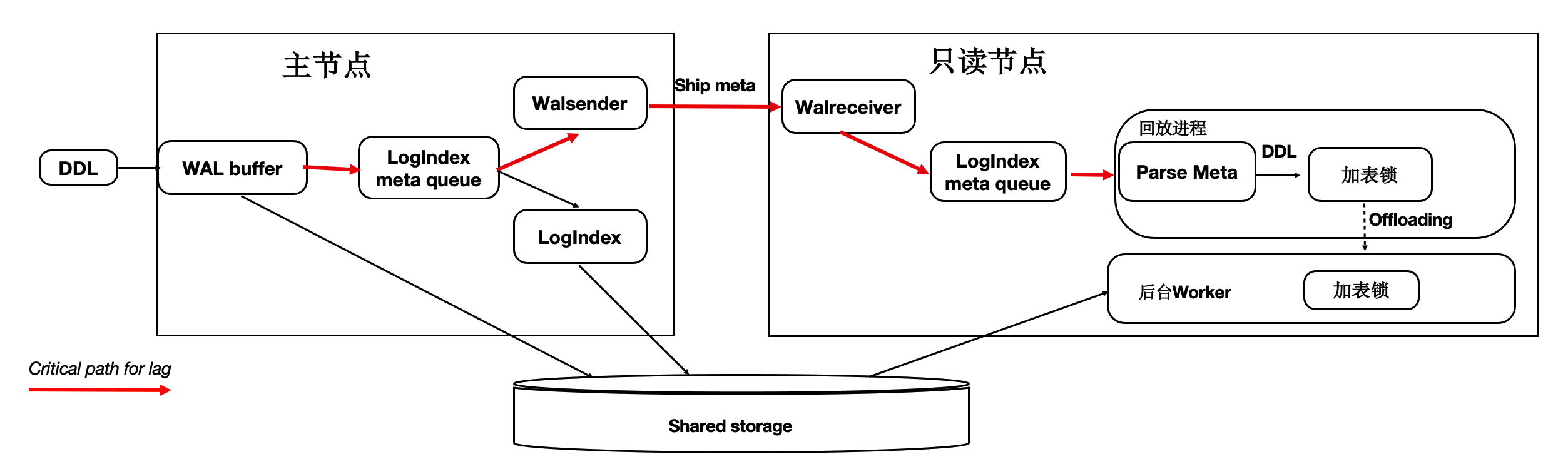
通过上述优化,能够保证回放进程一直处于平滑的状态,不会因为去等 DDL 而阻塞了回放的关键路径。

上述 3 个优化之后,极大的降低了复制延迟,能够带来如下优势:
读写分离:负载均衡,更接近 Oracle RAC 使用体验。
高可用:加速 HA 流程。
稳定性:最小化未来页的数量,可以写更少或者无需写页面快照。
5 Recovery 优化
5.1 背景
数据库 OOM、Crash 等场景恢复时间长,本质上是日志回放慢,在共享存储 Direct-IO 模型下问题更加 突出。

5.2 Lazy Recovery
上述内容介绍通过 LogIndex 在只读节点上做到了 Lazy 的回放,在主节点重启后的 recovery 过程中, 本质也是在回放日志,因此,可以借助 Lazy 回放来加速 recovery 的过程:

从 checkpoint 点开始逐条去读 WAL 日志。
回放完 LogIndex 日志后,即认为回放完成。
recovery 完成,开始提供服务。
真正的回放被 offload 到了重启之后进来的 session 进程中。
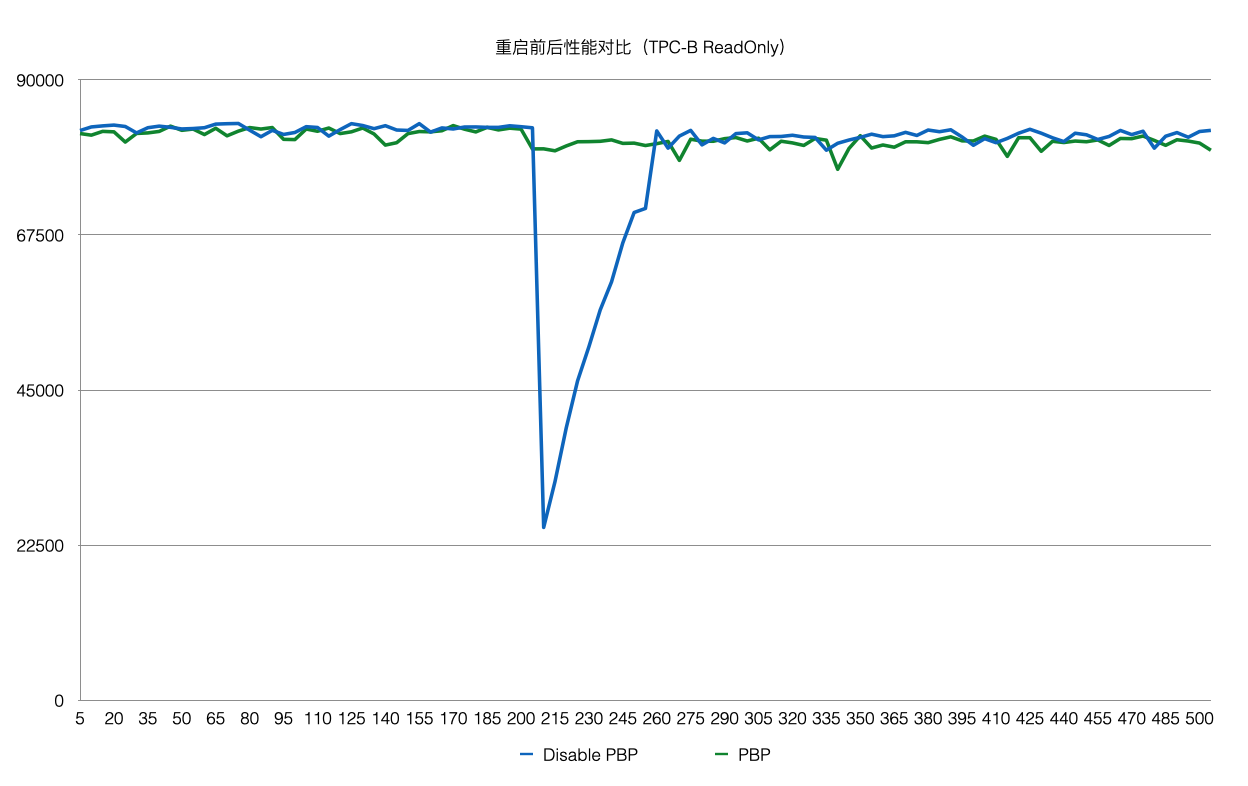
优化之后(回放 500 MB 日志量),如下图所示:
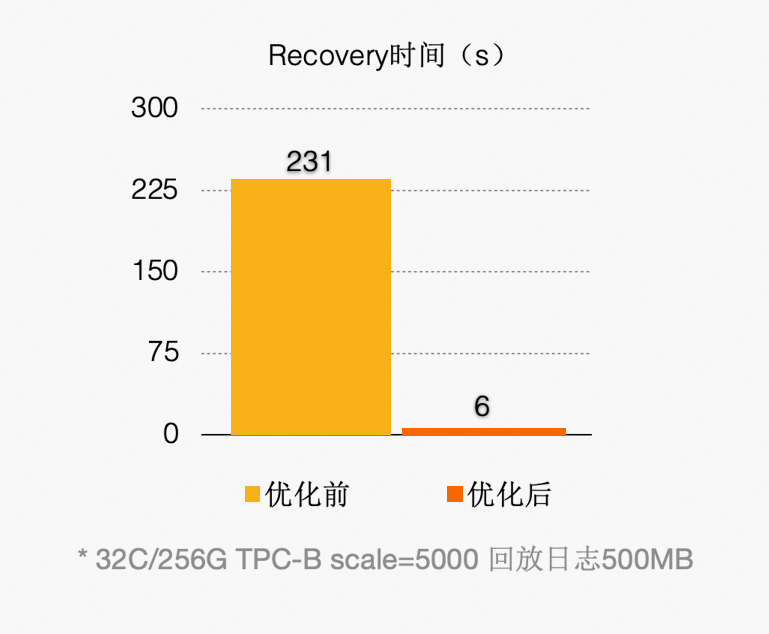
5.3 Persistent BufferPool
上述方案优化了在 recovery 的重启速度,但是在重启之后,session 进程通过读取 WAL 日志来回放想 要的 page。表示为在 recovery 之后会有短暂的响应慢的问题。优化的办法为在数据库重启时 BufferPool 并不销毁,如下图所示:crash 和 restart 期间 BufferPool 不销毁。
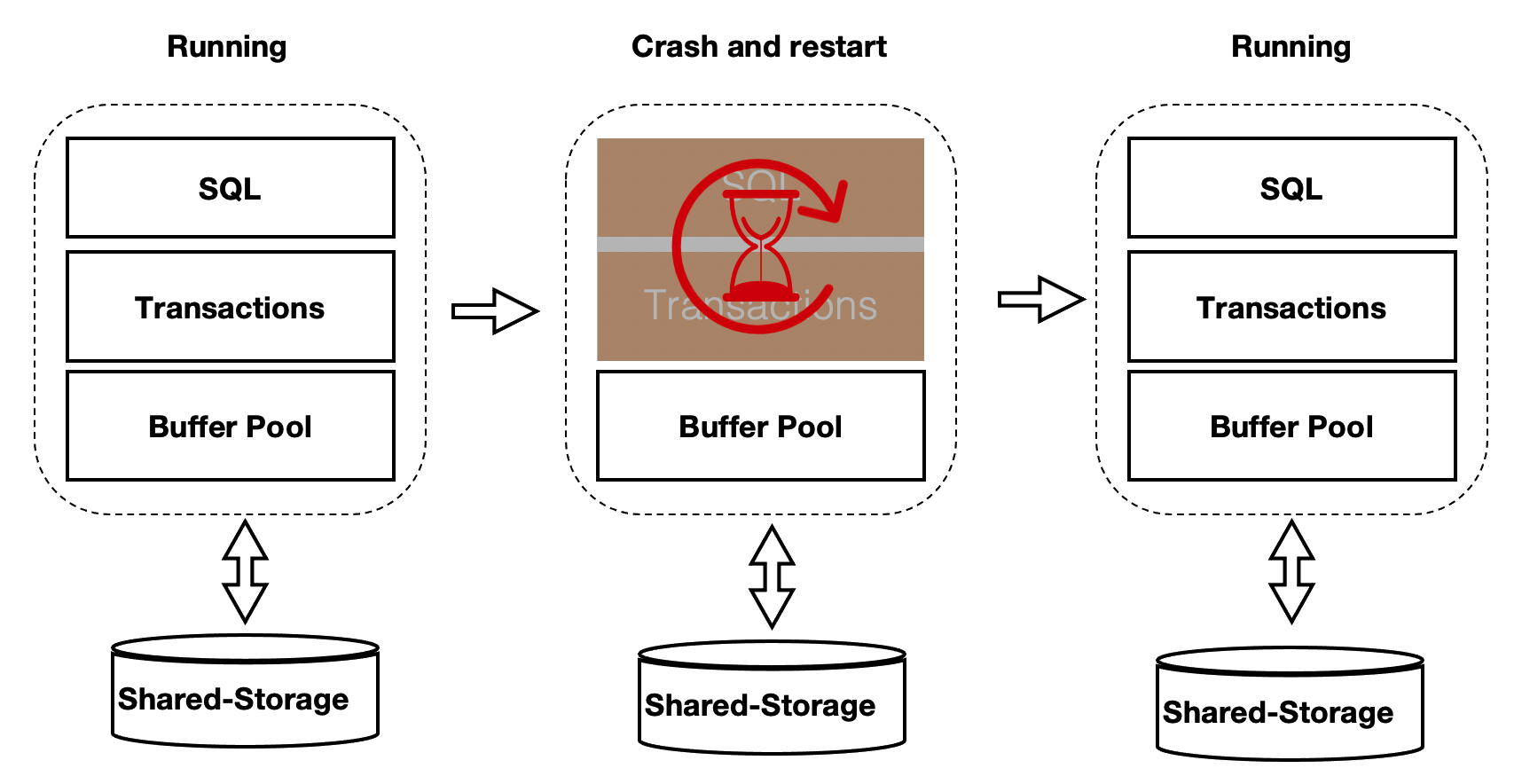
内核中的共享内存分成 2 部分:
全局结构,ProcArray 等。
BufferPool 结构;其中 BufferPool 通过具名共享内存来分配,在进程重启后仍然有效。而全局结 构在进程重启后需要重新初始化。
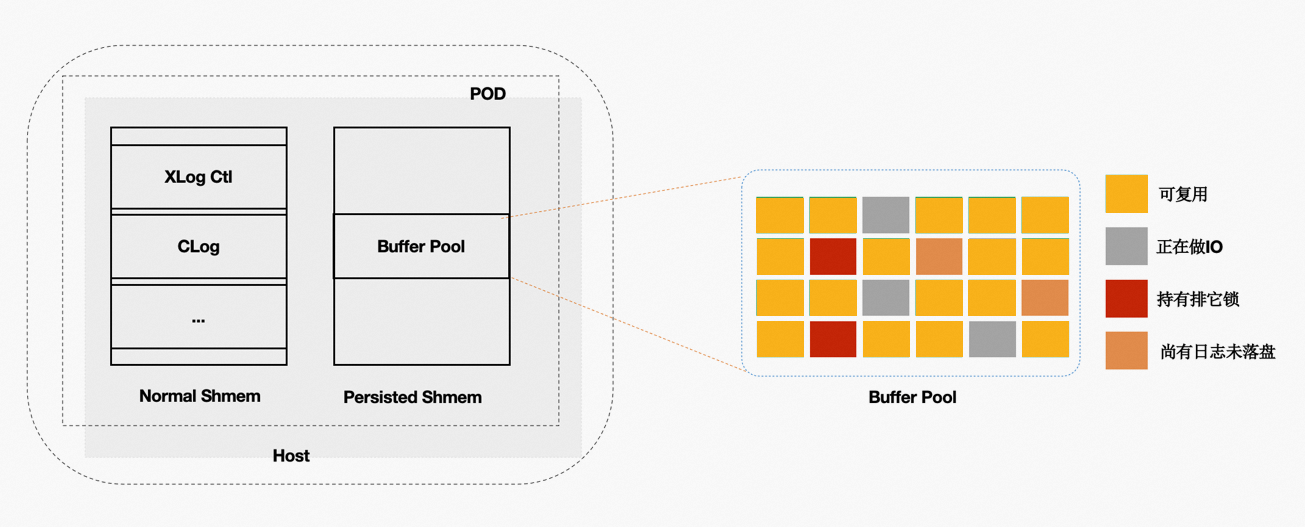
而 BufferPool 中并不是所有的 Page 都是可以复用的。例如:在重启前,某进程对 Page 上 X 锁,随后 crash 了,该 X 锁就没有进程来释放了。因此,在 crash 和 restart 之后需要把所有的 BufferPool 遍历 一遍,剔除掉不能被复用的 Page。另外,BufferPool 的回收依赖 kubernetes。该优化之后,使得重 启前后性能平稳。