- 1 Introduction
- 2 DESIGN OVERVIEW
- 2.1 Goals
- 2.2 Criteria of Design
- 3 架构图
- 3.1 Application Layer
- 3.2 Proxy Layer
- 3.3 Data Service Layer
- 3.4 Zones
- 3.5 表
- 3.6 Node
- 3.7 SQL Engine
- 3.8 Multi-tenancy
- 3.9 Resource Isolation.
- 3.10 Features
- 4 STORAGE ENGINE
- 5 TRANSACTION PROCESSING ENGINE
- 6 TPC-C BENCHMARK TEST
- 7 LESSONS IN BUILDING OCEANBASE
本文为摘录,原文为: attachments/pdf/d/p3385-xu.pdf
1 Introduction
2 DESIGN OVERVIEW
2.1 Goals
- Fast scale-out (scale-in) on commodity hardware to achieve high performance and low TCO.
- Cross-region deployment and fault tolerance.
2.2 Criteria of Design
3 架构图
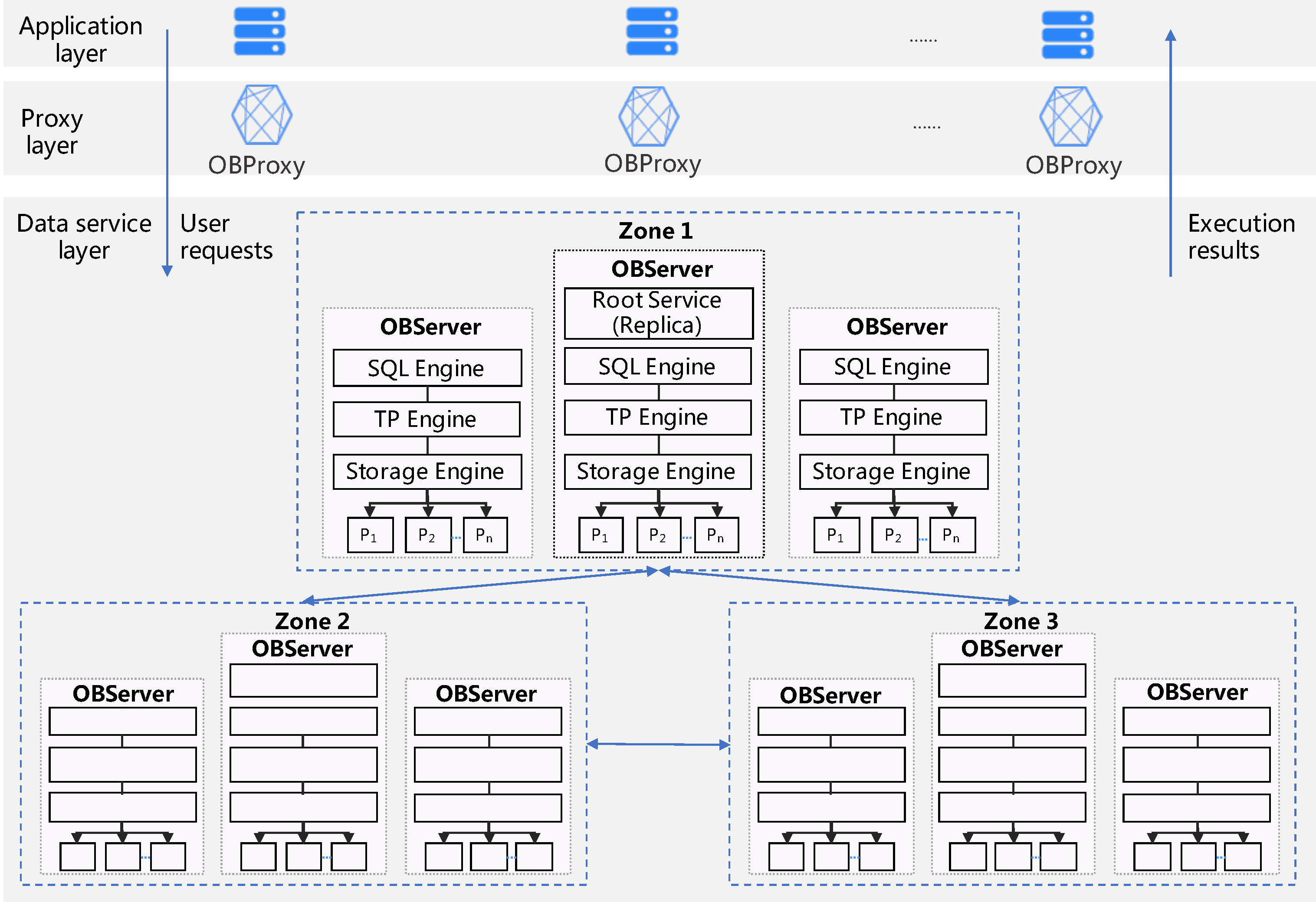
Figure 1: OceanBase 架构图
3.1 Application Layer
3.2 Proxy Layer
3.3 Data Service Layer
3.4 Zones
- Zones can be restricted to one region or spead over multiple regions.
- 事务通过 Paxos 在多个区域中复制 Transactions are replicated among the zones, using Paxos.
3.5 表
- 由用户显式地进行分区,并作为数据分布和负载均衡的基本单元
- 每个分片在每个 zone 中都有一个副本
3.6 Node
- 每个 Node (OBServer) 与传统的 RDMS 相似。
- 从 SQL 生成执行计划
- 如果是 local plan , 直接执行
- 否则, 通过两阶段提交协议来执行,
- 此时该节点作为 coordinator
- 当 Paxos 组中多数节点的 redo log 持久化后,才提交事务
3.7 SQL Engine
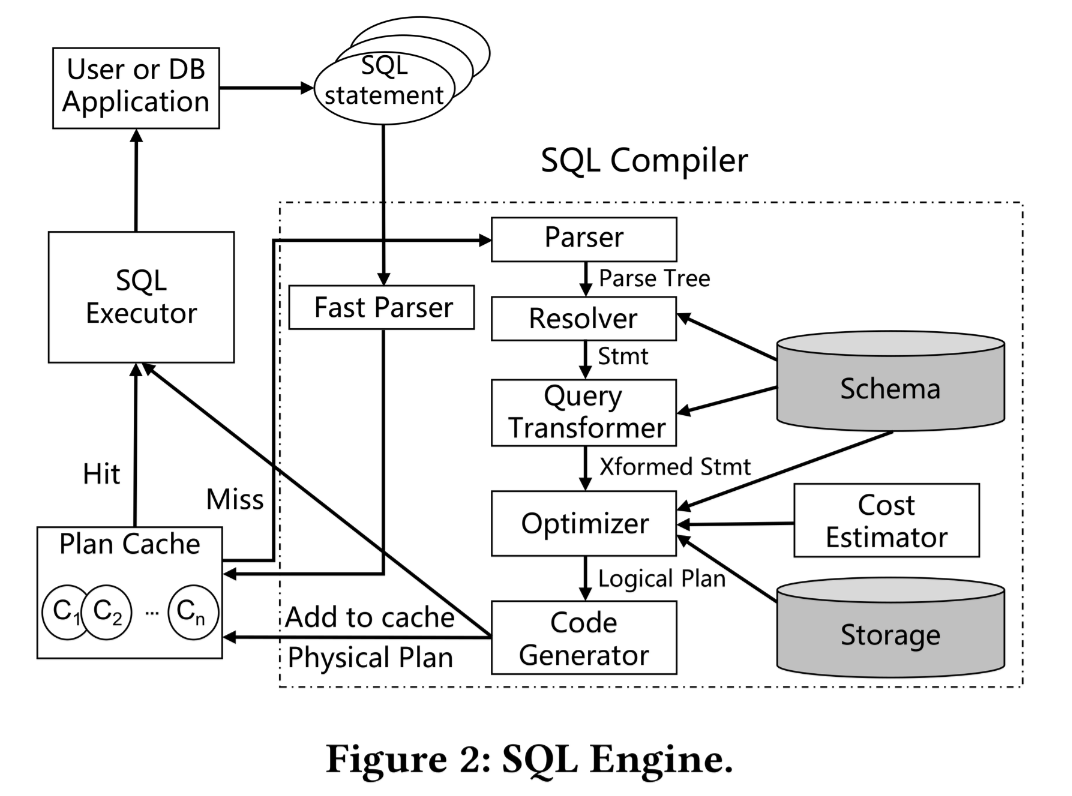
3.7.1 plan cache
- 收到请求后,仅进行简单的词法分析,然后在 plan cache 中匹配缓存的计划,找不到时候再去走完整的解析流程。
- 10x 提升。。。
3.8 Multi-tenancy
3.8.1 System Tenant 系统租户
系统内置,主要功能:
- 作为系统表的容器 – 系统表都存储在系统租户的空间内
- 。。。
- 。。。
3.8.2 Ordinary Tenant 普通髭胡
3.9 Resource Isolation.
3.10 Features
4 STORAGE ENGINE
基于 LSM-tree, 支持非对称数据块读写,日常增量 compaction, 和不同的副本类型。
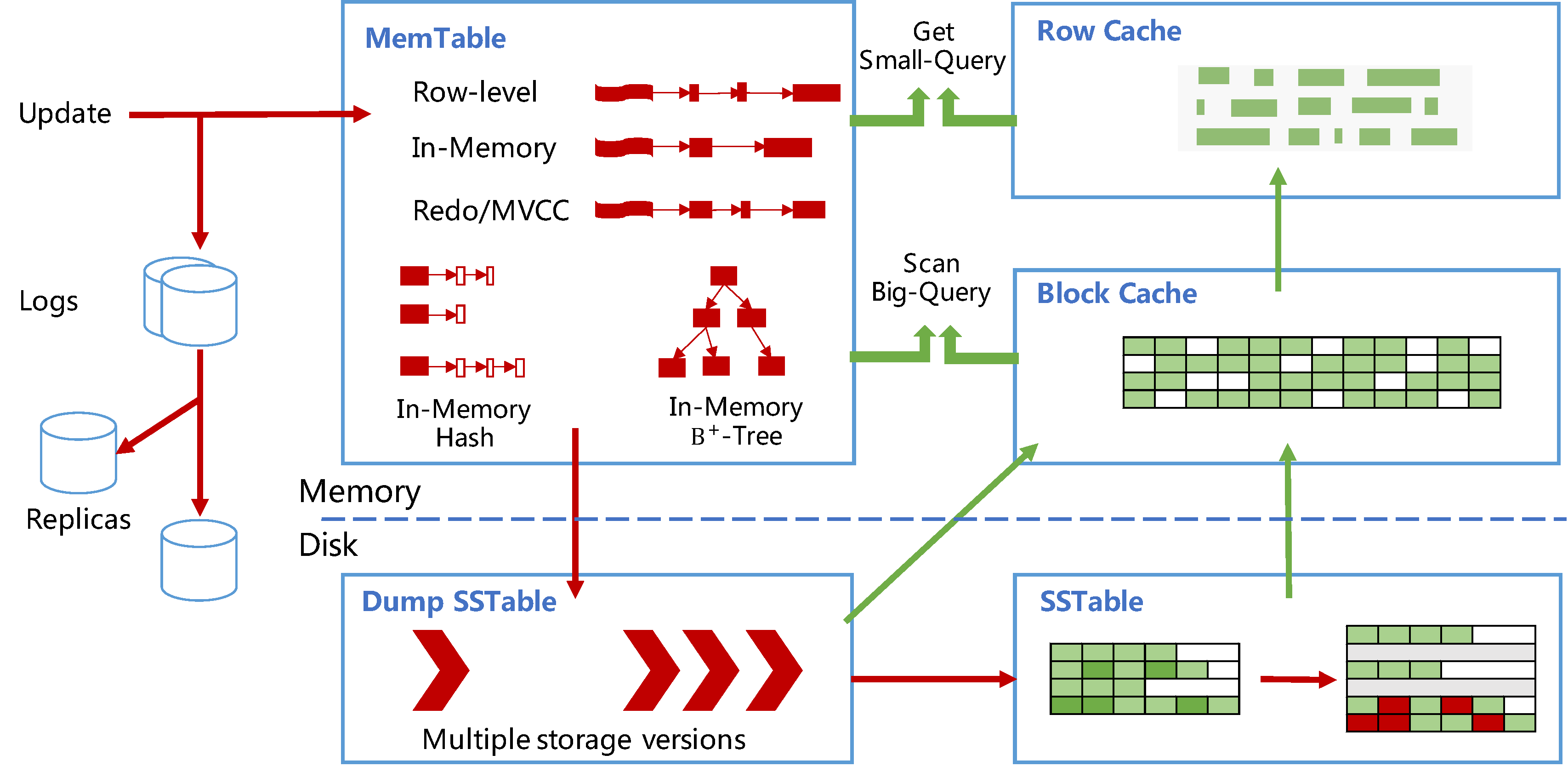
Figure 3: OB 的存储引擎
4.1 LSM Tree-Based Architecture
数据分成两部分:
- 静态基准数据 (static baseline data): 存储于 SSTable 中
- 动态增量数据 (dynamic incremental data) : 存储于 MemTable 中
SSTable & MemTable
- SSTable 为只读数据,生成之后就不再发生更改
- MemTable 支持读写操作,只存在内存中
- DML 操作 MemTable
- MemTable 打到一定大小以后, dump 到磁盘,生成 SSTable
- 查询针对两种存储分别进行,然后进行合并后返回给客户端
- 针对 SSTable 实现了 Block 缓存和行缓存,以减少对基线数据的随机访问
Compaction
Minor Compaction
- 内存中数据达到一定大小后,开始进行 minor compaction
- Minor Compaction 将 MemTable 转换成为 SSTable
Major Compaction
- 由系统每天进行增量的 Major Compaction
- Major Compaction 将 SSTable 和当天发生的变化进行合并,形成新版本的基线
该设计导致每次查询需要读取基准数据和增量数据, OB 做了很多优化
- 缓存 (block 级与行级)
- BloomFilter: 用于进行 empty checks
4.2 Asymmetric Read and Write
OB 实现了非对称读写。
- 读:
- 基本单元为 microblock
- 4K 或者 8K
- 写:
- 基本单元为 macroblock
- 2MB
- macroblock 同时也是存储系统的分配和垃圾回收的基础单元
- 多个 microblock 组装成一个 macroblock
- 磁盘使用更高效
- 但造成了一定程度上的写放大
4.3 Daily Incremental Major Compaction
- 数据且分成 2MB 大小的 macroblock, Major Compaction 中:
- 数据有修改,则重写该 block
- 数据无修改,则在新的 baseline 中直接重用,无 IO 开销
- 因此 Compaction 开销比 LevelDB RockDB 更小
4.4 Replica Type
有多种类型的副本:
full replica 完全副本,包含
- 基线数据
- 增量数据
- redo log
Data replica, 数据副本
- 包括基准数据和 relod log
- 根据需要从完全副本拷贝 minor compactions (compacted mutabtions)
- 重做完日志后,可以升级至完全副本
- 与完全副本相比,节省 CPU 和内存资源:
- 不必重做日志
- 没有 MemTable
Log Replica 日志副本
- 仅包含 redo log
- 作为 Paxos 组的成员
- 部署两个完全副本和一个日志副本,则:
拥有高可用特性
存储和内存开销大大减少

5 TRANSACTION PROCESSING ENGINE
5.1 Partition and Paxos Group
- Partition 分片是数据分布、负载均衡和 Paxos 同步的基础单元
- 每个分片一个 Paxos Group
5.2 Timestamp Service
- 使用 timestamp Paxos group 来实现时间戳服务的高可用
- timestamp paxos group 的 leader 与表分片的 paxos group leader 通常放在一个区域(region)中
5.3 Transaction Processing
5.4 Isolation Level
- read committed: default isolation level
- 也支持 snapshot isolation
5.5 Replicated Table
synchronously replicated table
- 变更需要等所有节点完成
- 慢
asynchronously replicated table
- 等待 paxos group 中的多数完成即可
- 快,但不保证所有节点的数据都为最新
- 如果查询中某节点遇到了老版本的数据,需要访问远端副本
6 TPC-C BENCHMARK TEST
7 LESSONS IN BUILDING OCEANBASE
7.1 From NoSQL to NewSQL
- 应用层不应将数据库尊为一个 key-value 存储系统来用,也不应该倚赖某些数据的高级特性
- 存储过程对某些 OLTP 应用来说仍有很大的价值
- 对于使用分布式数据库的应用来说,每个事务、每个 SQL 都应该有超时机制:分布式系统的出错率更高一些(网络,节点等原因)