本文为摘录,原文为: attachments/pdf/f/p2257-jahangiri.pdf
1 ABSTRACT
- 探索分片数量对 HHJ 性能的影响
- propose a new lower bound for number of partitions
- design and evaluate different partition insertion techniques to maximize memory utilization with the lest CPU cost
2 INTRODUCTION
HHJ: Hybrid Hash Join
算法
- 将数据划分成多个分片
- 一个分片在内存中
- 其余分片溢出到磁盘
- 处理内存中的分片
- 多趟,处理其余分片
- 将数据划分成多个分片
分片数量以及选择哪个分片放在内存中,是生成 operator 时候静态指定的
- 依据代价模型
- 有不足之处:
- 假设 join 列的值程均匀分布
- 代价模型倚赖于精确的统计信息,如 输入大小等。
然而收集、访问或者预测这些信息有时并不可行:
- 外部表的统计信息经常不准或者缺失
- join 输入的来源如果是其他算子,则其大小可能不准确
3 BACKGROUND
3.1 Hybrid Hash Join
3.1.1 Grace Hash Join (GHI)
- 使用内存作为中间介质,将数据划分成内存中可以装下的分片,然后在做 join
- 算法
- Grace Hash Join 连续的处理 build 和 probe 过程
- 每个分片都写入磁盘,存程单独的文件
- 重复划分过程,直到一个分片可以装入内存为止
- 每个分片创建一个 hash table, 开始 join
- 适用于 小表 (build 表) 也远远大于内存时候
3.1.2 Simple Hash Join (SHJ)
- 始终在内存中保存一部分数据,以期减少 IO 的总体开销
- 算法
- records 哈希划分成两个部分:
- 内存分片
- 溢出分片
- records 哈希划分成两个部分:
- 适用于内存可以装下大部分小表数据的时候
3.1.3 Hybrid Hash Join (HHJ)
混合了 GHJ & SHJ:
- 通过划分分片来避免不必要的数据比较
- 使用内存来保存一个分片及其对应的哈希表
如图 1 (a) 所示。
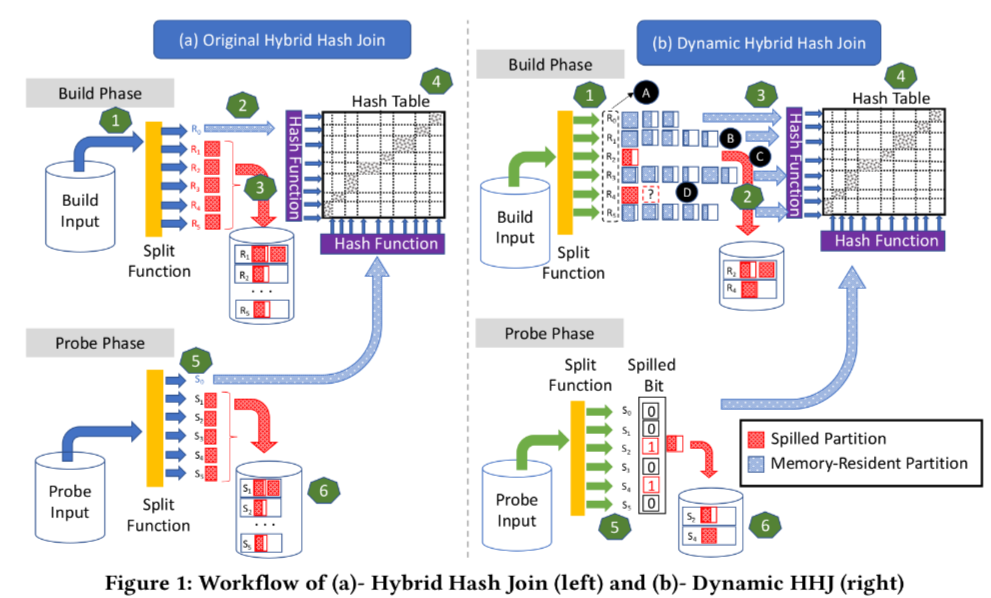
步骤:
Build Phase, 使用拆分函数 (split function) 将输入进行哈希划分,其结果:
- 划分进入内存分片的,驻留内存
- 其余溢出到磁盘中对应文件
- 由内存分片构建哈希表
Probe Phase 使用同样的拆分函数 (split function) 将输入进行哈希划分,其结果:
- 划入内存分片的,直接 probe
- 其余写入磁盘的对应文件
- 处理完内存分片后,逐一处理溢出文件。
3.1.4 Dynamic Hybrid Hash Join
与 HHJ 相比:
- HHJ: 选择预先定义的一个分片常驻内存
- DHHJ: 使用动态降级策略来选择内存分片:
如图 1 (b) 所示,
- Build Phase:
- build 开始时候,所有分片都在内存中,
- 只要内存还够用,始终使用内存来保存分片
- 随着输入的增加,由于数据可能倾斜,各个分片的大小开始不一样
- 当内存耗尽时, 动态选择 一个分片进行溢出操作
该方法尤其适用于当输入大小或者join 属性的分布未知或者不准确的时候。