本文为摘录,原文为: attachments/pdf/5/p2161-zhang.pdf
1 ABSTRACT
- 云存储中很大一部分数据很少被访问,被称为 冷数据 。
- 精确地识别和有效地管理成本效益高的存储中的冷数据是云提供商面临的主要挑战之一,需要平衡降低成本和提高系统性能。
- 为此,提出了 SA-LSM 来利用生存分析(Survival Analysis)的方式来处理 LSM-tree 键值(KV)存储。
- 传统上,LSM-tree 的数据布局是由写操作和压实操作共同确定的。
- 然而,该过程默认情况下并未充分利用数据记录的访问信息,导致次优的数据布局,对系统性能产生负面影响。
- SA-LMS 使用生存分析,一种在生物统计学中常用的统计学习算法来优化数据布局。
- 当与合适的 LSM-tree 实现结合使用时,SA-LSM 可以使用历史信息和访问痕迹准确预测冷数据。
- 具体实现方面,将 SA-LSM 应用于商业化开源 LSM-tree 存储引擎 X-Engine 中
- 了使部署更加灵活,还设计了一种非侵入式架构,可以将 CPU 密集型任务(例如模型训练和推断)卸载到外部服务上。
- 在真实工作负载上的广泛实验表明,与现有技术相比,SA-LSM 可以将尾延迟降低高达 78.9%。
- 这种方法的通用性和显著性能提升在相关应用中具有巨大潜力。
2 INTRODUCTION
为了降低存储成本,LSM 树变成了一种越来越受欢迎的架构。它引入了多层异构存储:
- 上层被映射到快速存储,例如固态硬盘(SSD),
- 下层则映射到慢速存储,例如硬盘驱动器(HDD)。
- 其中一个关键组件是压缩策略,它确定如何在不同的层之间动态分配和移动数据记录。
传统的 LSM-tree 数据布局通常是由写操作和压实操作共同决定的
- 其中背景压实操作定期将数据记录合并到持久存储上,以改善读写和空间放大。
- 默认情况下,这个过程并没有充分利用数据记录的访问信息,从而导致子优的数据布局,对系统性能产生负面影响。
- 当不同的 LSM 层面映射到异构存储上时,这种影响甚至更加明显。
因此,我们设计了基于生存分析的 SA-LSM 来增强压实策略,这是一种在生物统计学中常用的统计学 习算法,可优化这一过程中的数据布局。
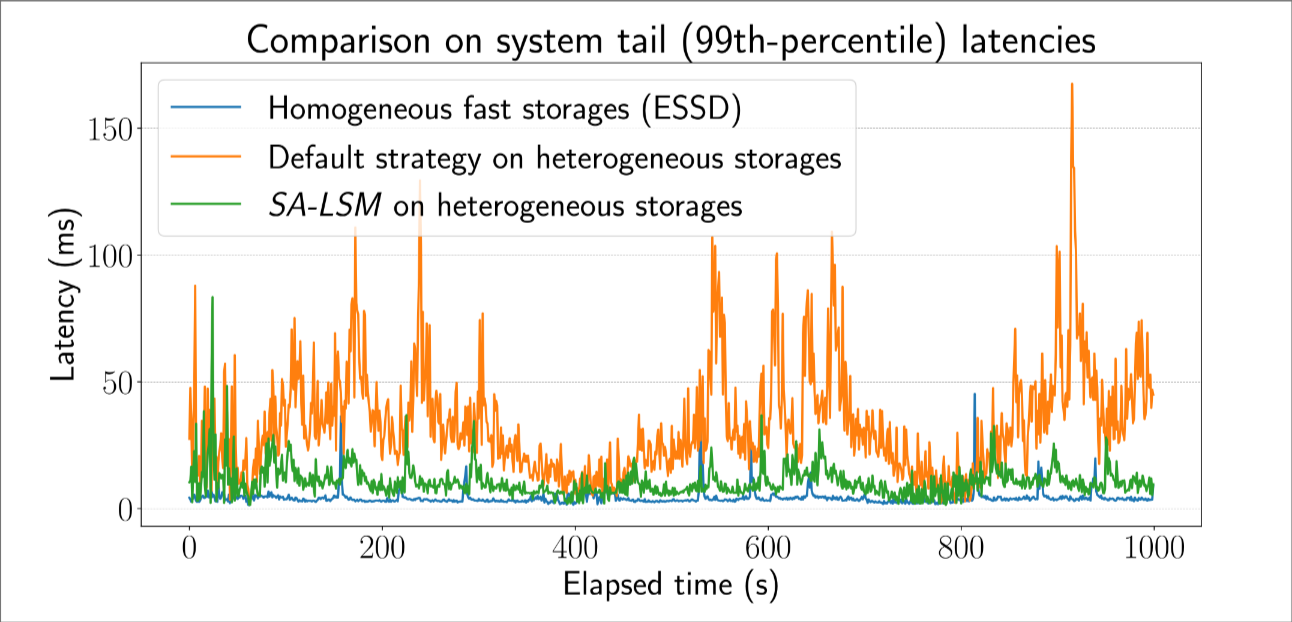
Figure 1: 几种 LSM tree 存储布局的延迟