- 1 Resource Group 简介
- 2 Resource Group 使用
- 2.1 创建资源组
- 2.2 将资源组分配给角色
- 2.3 修改资源组配置
- 2.4 删除资源组
- 2.5 取消资源组中的正在运行或已排队的事务
- 3 Resource Group 监控
- 4 Resource Group 实现分析
- 4.1 并发限制
- 4.2 CPU 限制
- 4.3 内存限制
- 4.4 Resource Group 监控
- 5 常见问题
- 6 总结
本文为摘录,原文为: https://blog.csdn.net/u013970710/article/details/115433014
Greenplum 是一款广泛应用的开源 MPP 数据库的产品,兼容 PostgreSQL 生态,被广泛应用与大数据的存储与分析。
Resource Group 是 Greenplum 的一种资源管理方式。 Resource Group 由 GP5 开始被支持,相比于早期的 Resource Queue 的 资源管理方式,具有支持更细粒度的资源管理、 支持组内资源共享等优点。本文会介绍 Resource Group 的使用方式,从源码 角度分析它的实现,以及介绍一些使用中遇到的高频问题。
1 Resource Group 简介
Resource Group 是 Greenplum 的一种资源管理方式,能够细粒度定义对不同数据库角色(用户)的资源使用限制,支持通过 SQL 语句的方式进行配置。 Resource Group 支持进行三种类型的资源限制:并发限制、 CPU 限制、内存限制。
超级用户可以通过 SQL 在数据库内定义多个资源组,并设置每个资源组的资源限制。在一个数据库中,每个资源组可以关联一 个或多个数据库用户,而每个数据库用户只能归属于单个资源组。资源组支持的资源限制配置如下:
| CONCURRENCY | 资源组中允许的最大并发事务数,包括活动和空闲事务。 |
|---|---|
| CPU_RATE_LIMIT | 此资源组可用的 CPU 资源百分比。 |
| CPUSET | 为该资源组保留的 CPU 核心数。 |
| MEMORY_LIMIT | 该资源组可用的内存资源百分比。 |
| MEMORY_SHARED_QUOTA | 提交到该资源组的事务之间共享的内存资源百分比。 |
| MEMORY_SPILL_RATIO | 内存密集型事务的内存使用阈值。当事务达到此阈值时,它将溢出到磁盘。 |
CONCURRENCY代表最大并发事务数;CPU_RATE_LIMIT代表以百分比形式限制 CPU 使用,各个资源组设置的CPU_RATE_LIMIT之和不超过100%;CPUSET代表以 CPU 核的形式限制 CPU ,设置具体使用哪几个 CPU 逻辑核;MEMORY_LIMIT代表资源组最多能占用的集群可用内存的百分比,- 由 MEMORY_LIMIT 设定的部分属于资源组的固定份额,
- 而各个资源组 MEMORY_LIMIT 之和低于 100% 的部分,被划分所有资源组的共享内存池;
- Bad boy…
- MEMORY_SHARED_QUOTA 代表资源组内用于各个事务共享的内存比例;
- MEMORY_SPILL_RATIO 代表溢出到磁盘的内存使用阈值。
CREATE RESOURCE GROUP rgroup1 WITH (
CONCURRENCY=10,
CPU_RATE_LIMIT=20,
MEMORY_LIMIT=25,
MEMORY_SHARED_QUOTA=20,
MEMORY_SPILL_RATIO=20
);
除了 Resource Group ,GP 早期还支持 Resource Queue 的资源管理方式, Resource Queue 通过指定 MEMORY_LIMIT 、 ACTIVE_STATEMENTS 、PRIORITY 、MAX_COST 字段,配置对于各个资源队列的内存、 CPU 、并发限制, Resource Group 相对 Resource queue 存在以下优势:
| 特性 | Resource Groups | Resource Queues |
|---|---|---|
| CPU 管理 | 细粒度(Cgroup) | 基于粗粒度的优先级 |
| 内存限制 | 细粒度 | 粗粒度 |
| 并发控制 | 事务级别 | 语句级别 |
| 管理 DDL Utility 语句 | 是 | 否 |
| segment 级别监控 | 是 | 否 |
| 组内内存共享 | 是 | 否 |
Resource Group 通过 Master 上的并发锁实现对并发的限制,通过 cgroup 实现对 cpu 的限制,支持对内存基于 vmtracker 和 cgroup 进行两种方式的限制。
2 Resource Group 使用
2.1 创建资源组
使用 CREATE RESOURCE GROUP 命令创建新资源组。
为角色创建资源组时,必须提供 CPU_RATE_LIMIT 或 CPUSET 和 MEMORY_LIMIT 限制值。这些限制标识要分配给此资源组的数据 库资源的百分比。例如,要创建名为 rgroup1 的资源组,其 CPU 限制为 20 ,内存限制为 25 :
CREATE RESOURCE GROUP rgroup1 WITH (CPU_RATE_LIMIT=20, MEMORY_LIMIT=25);
CPU 限制为 20 由 rgroup1 分配到的每个角色共享。同样,内存限制为 25 由 rgroup1 分配到的每个角色共享。rgroup1 使用 默认的 MEMORY_AUDITOR vmtracker 和默认的 CONCURRENCY 设置为 20 。
数据库包含两个默认资源组: admin_group 和 default_group 。启用资源组时,将为未明确分配资源组的任何角色分配角色功 能的默认组。 SUPERUSER 角色分配了 admin_group ,非管理员角色分配了名为 default_group 的组。
使用以下资源限制创建默认资源组 admin_group 和 default_group :
| 限制类型 | admin_group | default_group |
|---|---|---|
| CONCURRENCY | 10 | 20 |
| CPU_RATE_LIMIT | 10 | 30 |
| CPUSET | -1 | -1 |
| MEMORY_LIMIT | 10 | 30 |
| MEMORY_SHARED_QUOTA | 50 | 50 |
| MEMORY_SPILL_RATIO | 20 | 20 |
| MEMORY_AUDITOR | vmtracker | vmtracker |
默认资源组 admin_group 和 default_group 的 CPU_RATE_LIMIT 和 MEMORY_LIMIT 值对分段主机上的总百分比有贡献。
2.2 将资源组分配给角色
Greenplum 资源组可用于分配给一个或多个角色(用户)。使用 CREATE ROLE 或 ALTER ROLE 命令的 RESOURCE GROUP 子句将资 源组分配给数据库角色。如果未为角色指定资源组,则会为角色分配角色功能的默认组。 SUPERUSER 角色分配了 admin_group ,非管理员角色分配了名为 default_group 的组。
使用 ALTER ROLE 或 CREATE ROLE 命令将资源组分配给角色。例如:
ALTER ROLE bill RESOURCE GROUP rg_light;
CREATE ROLE mary RESOURCE GROUP exec;
用户可以将资源组分配给一个或多个角色。如果已定义角色层次结构,则将资源组分配给父角色不会向下传播到该角色组的成员。
如果要从角色中删除资源组分配并将角色分配为默认组,请将角色的组名称分配更改为 NONE 。例如:
ALTER ROLE mary RESOURCE GROUP NONE;
2.3 修改资源组配置
ALTER RESOURCE GROUP 命令可以修改资源组配置。要更改资源组的限制,请指定组所需的新值。例如:
ALTER RESOURCE GROUP rg_role_light SET CONCURRENCY 7;
ALTER RESOURCE GROUP exec SET MEMORY_LIMIT 25;
ALTER RESOURCE GROUP rgroup1 SET CPUSET '2,4';
注意 : 用户无法将 admin_group 的 CONCURRENCY 值设置或更改为 0 。
2.4 删除资源组
DROP RESOURCE GROUP 命令会删除资源组。要删除角色的资源组,不能将该组分配给任何角色,也不能在资源组中激活或等待任何事务。
DROP RESOURCE GROUP exec;
2.5 取消资源组中的正在运行或已排队的事务
在某些情况下,用户可能希望取消资源组中的正在运行或排队的事务。例如,用户可能希望删除在资源组队列中等待但尚未执行 的查询。或者,用户可能希望停止执行时间太长的正在运行的查询,或者在事务中处于空闲状态并占用其他用户所需的资源组事 务插槽的查询。
要取消正在运行或排队的事务,必须首先确定与事务关联的进程 ID (pid )。获得进程 ID 后,可以调用
pg_cancel_backend() 来结束该进程。
例如,要查看与当前活动或在所有资源组中等待的所有语句关联的进程信息,请运行以下查询。如果查询未返回任何结果,则任 何资源组中都没有正在运行或排队的事务。
SELECT rolname, g.rsgname, procpid, waiting, current_query, datname
FROM pg_roles, gp_toolkit.gp_resgroup_status g, pg_stat_activity
WHERE pg_roles.rolresgroup=g.groupid
AND pg_stat_activity.usename=pg_roles.rolname;
示例部分查询输出:
rolname | rsgname | procpid | waiting | current_query | datname
---------+----------+---------+---------+-----------------------+---------
sammy | rg_light | 31861 | f | <IDLE> in transaction | testdb
billy | rg_light | 31905 | t | SELECT * FROM topten; | testdb
使用此输出来标识要取消的事务的进程 ID (procpid ),然后取消该进程。例如,要取消上面示例输出中标识的待处理查询:
SELECT pg_cancel_backend(31905);
用户可以在 pg_cancel_backend() 的第二个参数中提供可选消息,以向用户指示进程被取消的原因。
3 Resource Group 监控
本节主要介绍如何通过系统视图监控集群的资源组,包括各个资源组的配置,各个资源组的资源使用情况等。
以下是资源组相关的监控项的含义:
| rsgname | 资源组名 |
|---|---|
| groupid | 资源组 oid |
| cpu | 当前资源组的 cpu 利用率 |
| memory_used | 当前资源组实际使用的内存总量 |
| memory_available | 当前资源组可用的内存总量 |
| memory_quota_used | 当前资源组固定份额部分实际使用的内存总量 |
| memory_quota_available | 当前资源组固定份额部分可用的内存总量 |
| memory_quota_granted | 当前资源组固定份额部分的总体分配量 |
| memory_shared_used | 当前资源组共享部分实际使用的内存总量 |
| memory_shared_available | 当前资源组共享部分可用的内存总量 |
| memory_shared_granted | 当前资源组共享部分的总体分配量 |
正常情况下,各个资源组监控项有以下关系:
memory_used = memory_quota_used + memory_shared_used
available = memory_quota_granted + memory_shared_granted - memory_used
memory_quota_granted = memory_quota_used + memory_quota_available
memory_shared_granted = memory_shared_used + memory_shared_available
3.1 查看资源组限制
gp_resgroup_config 系统视图显示所有的资源组配置。
SELECT * FROM gp_toolkit.gp_resgroup_config;
3.2 查看资源组查询状态和 CPU/ 内存使用情况
gp_resgroup_status 系统视图可以查看资源组的状态和活动。该视图显示正在运行和排队的事务数。它还显示资源组的实时 CPU 和内存使用情况。
SELECT * FROM gp_toolkit.gp_resgroup_status;
3.3 查看每个主机的资源组 CPU/ 内存使用情况
通过 gp_resgroup_status_per_host 系统视图,用户可以基于每个主机查看资源组的实时 CPU 和内存使用情况。
SELECT * FROM gp_toolkit.gp_resgroup_status_per_host;
3.4 查看每个 segment 的资源组 CPU/ 内存使用情况
通过 gp_resgroup_status_per_segment 系统视图,用户可以按每个 segment ,每个主机查看资源组的实时 CPU 和内存使用情 况。
SELECT * FROM gp_toolkit.gp_resgroup_status_per_segment;
3.5 查看分配给角色的资源组
要查看资源组到角色的分配,请对 pg_roles 和 pg_resgroup 系统表执行以下查询:
SELECT rolname, rsgname FROM pg_roles, pg_resgroup
WHERE pg_roles.rolresgroup=pg_resgroup.oid;
3.6 查看资源组的运行和待定查询
要查看资源组的运行查询,挂起的查询以及挂起的查询排队的时间,请检查 pg_stat_activity 系统表:
SELECT current_query, waiting, rsgname, rsgqueueduration
FROM pg_stat_activity;
4 Resource Group 实现分析
Greenplum 数据库是 MPP 架构,整体分为一个或多个 Master ,以及多个 segment ,数据在多个 segment 之间可以随机、哈 希、复制分布。在 Greenplum 中, Resource Group 的资源限制级别是事务级别。 Resource Group 会在各个 group 内部将资 源划分成并发量数目的 slot ,而每个事务在运行前排队等待获取 slot 。
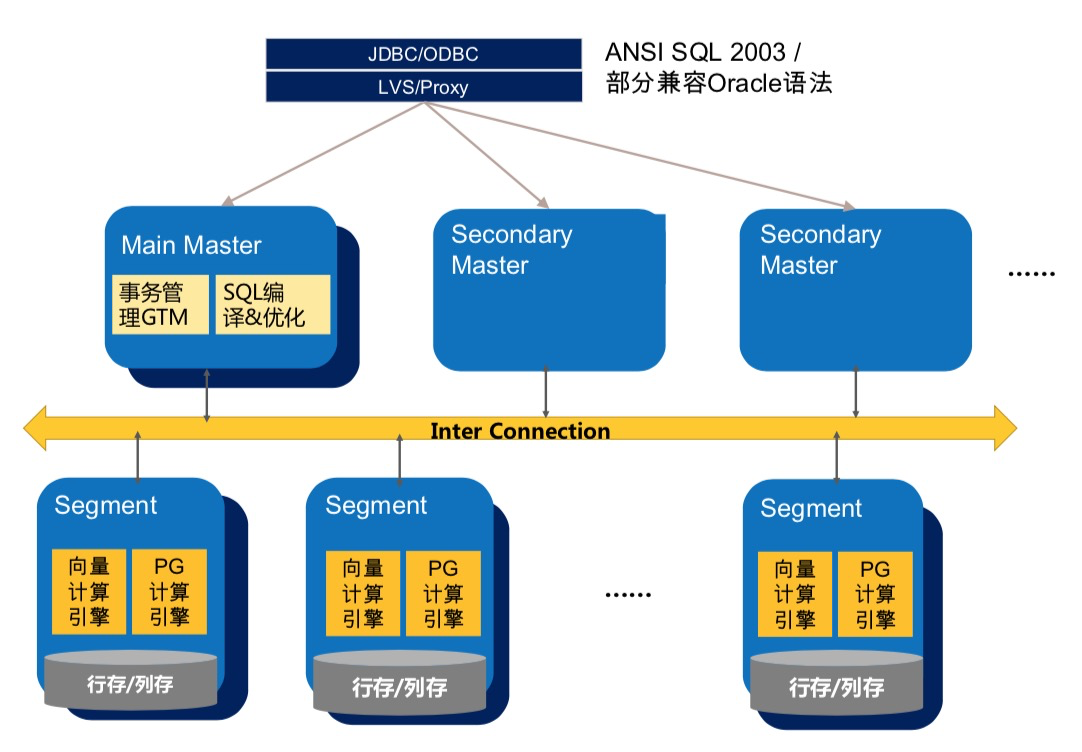
如上文所述, Resource Group 支持对并发、 CPU 和内存进行限制,本节会详细介绍对这几类资源进行限制的实现细节,以及 介绍对于资源组的监控是如何实现的。
Resource Group 的代码主要位于如下的路径和文件中:
src/backend/utils/resgroup
src/backend/utils/ressource_manager
src/backend/commands/resgroupcmds.c
4.1 并发限制
Resource Group 通过 Master 上的并发锁实现对并发的限制。用户连接到数据库集群时,首先会连接到 Master 节点,在开启事务时,会尝试获取 slot 。
static ResGroupSlotData *
groupGetSlot(ResGroupData *group)
{
ResGroupSlotData *slot;
ResGroupCaps *caps;
int32 slotMemQuota;
Assert(LWLockHeldExclusiveByMe(ResGroupLock));
Assert(Gp_role == GP_ROLE_DISPATCH);
Assert(groupIsNotDropped(group));
caps = &group->caps;
/* First check if the concurrency limit is reached */
if (group->nRunning >= caps->concurrency)
return NULL;
slotMemQuota = groupReserveMemQuota(group);
if (slotMemQuota < 0)
return NULL;
/* Now actually get a free slot */
slot = slotpoolAllocSlot();
Assert(!slotIsInUse(slot));
initSlot(slot, group, slotMemQuota);
group->nRunning++;
return slot;
}
Master 上通过比较资源组当前运行的事务数 group->nRunning ,与设定的并发数 concurrency ,保证限制实际运行的并发数 不高于设定值。 Greenplum 是多进程模型,各个资源组的计数量 group->nRunning 放在共享内存中,在 slot 的获取过程中, 会获取 ResGroupLock 类型的排他锁,以保证并发安全。
4.2 CPU 限制
Resource Group 通过 cgroup 实现对 cpu 的限制。在 resource group 创建或者修改时(比如 initCpu ),数据库会在操作 系统 cgroup 路径下,创建与 resource group oid 同名的 cgroup 路径,即做对应挂载。并根据设置的 CPU 配置,更新对应 cgroup 子路径下的 cpu.cfs_period_us 、cpu.cfs_quota_us 、cpu.shares 文件。
而在开始事务时,数据库会将当前进程关联到对应的 cgroup 子节点下,具体逻辑如下:
void
ResGroupOps_AssignGroup(Oid group, ResGroupCaps *caps, int pid)
{
bool oldViaCpuset = oldCaps.cpuRateLimit == CPU_RATE_LIMIT_DISABLED;
bool curViaCpuset = caps ? caps->cpuRateLimit == CPU_RATE_LIMIT_DISABLED : false;
/* needn't write to file if the pid has already been written in.
* Unless it has not been writtien or the group has changed or
* cpu control mechanism has changed */
if (IsUnderPostmaster &&
group == currentGroupIdInCGroup &&
caps != NULL &&
oldViaCpuset == curViaCpuset)
return;
writeInt64(group, BASETYPE_GPDB, RESGROUP_COMP_TYPE_CPU,
"cgroup.procs", pid);
writeInt64(group, BASETYPE_GPDB, RESGROUP_COMP_TYPE_CPUACCT,
"cgroup.procs", pid);
if (gp_resource_group_enable_cgroup_cpuset)
{
if (caps == NULL || !curViaCpuset)
{
/* add pid to default group */
writeInt64(DEFAULT_CPUSET_GROUP_ID, BASETYPE_GPDB,
RESGROUP_COMP_TYPE_CPUSET, "cgroup.procs", pid);
}
else
{
writeInt64(group, BASETYPE_GPDB,
RESGROUP_COMP_TYPE_CPUSET, "cgroup.procs", pid);
}
}
/*
* Do not assign the process to cgroup/memory for now.
*/
currentGroupIdInCGroup = group;
if (caps != NULL)
{
oldCaps.cpuRateLimit = caps->cpuRateLimit;
StrNCpy(oldCaps.cpuset, caps->cpuset, sizeof(oldCaps.cpuset));
}
}
数据库会将对应进程的 pid 写进子路径的 cgroup.procs 文件里,从而利用操作系统的 cgroup 能力对进程的 cpu 使用进行限 制。
4.3 内存限制
支持对内存基于 vmtracker 和 cgroup 进行两种方式的限制。在使用 cgroup 做内存限制的时候,它的应用原理与 CPU 限制类 似:为每个资源组创建一个 cgroup 子节点,在资源组创建和修改时,修改对应 cgroup 的内存管理配置文件 memory.limit_in_bytes 、 memory.usage_in_bytes ;事务运行时通过 pid 与对应 cgroup 关联,支持内存的限制。
而基于 vmtracker 进行内存限制时,则完全是由数据库本身进行高并发场景下的内存审计和分配,这里以内存统计量的修改为 例:
static int32
groupIncMemUsage(ResGroupData *group, ResGroupSlotData *slot, int32 chunks)
{
int32 slotMemUsage; /* the memory current slot has been used */
int32 sharedMemUsage; /* the total shared memory usage,
sum of group share and global share */
int32 globalOveruse = 0; /* the total over used chunks of global share*/
/* Add the chunks to memUsage in slot */
slotMemUsage = pg_atomic_add_fetch_u32((pg_atomic_uint32 *) &slot->memUsage,
chunks);
/* Check whether shared memory should be added */
sharedMemUsage = slotMemUsage - slot->memQuota;
if (sharedMemUsage > 0)
{
/* Decide how many chunks should be counted as shared memory */
int32 deltaSharedMemUsage = Min(sharedMemUsage, chunks);
/* Add these chunks to memSharedUsage in group,
* and record the old value*/
int32 oldSharedUsage = pg_atomic_fetch_add_u32((pg_atomic_uint32 *)
&group->memSharedUsage,
deltaSharedMemUsage);
/* the free space of group share */
int32 oldSharedFree = Max(0, group->memSharedGranted - oldSharedUsage);
/* Calculate the global over used chunks */
int32 deltaGlobalSharedMemUsage = Max(0, deltaSharedMemUsage - oldSharedFree);
/* freeChunks -= deltaGlobalSharedMemUsage and get the new value */
int32 newFreeChunks = pg_atomic_sub_fetch_u32((pg_atomic_uint32 *)
&pResGroupControl->freeChunks,
deltaGlobalSharedMemUsage);
/* calculate the total over used chunks of global share */
globalOveruse = Max(0, 0 - newFreeChunks);
}
/* Add the chunks to memUsage in group */
pg_atomic_add_fetch_u32((pg_atomic_uint32 *) &group->memUsage,
chunks);
return globalOveruse;
}
在进行内存限制时,对于某个 slot 的内存请求,首先会通过原子相加的方式从资源组的固定份额部分获取内存;而如果所需要 的内存超过固定份额的内存量,会尝试从资源组内的共享内存部分获取;如果依然无法获取到内存,则会尝试从全局的共享内存 获取。如果从全局共享内存依然无法获取到内存,则会返回 Out of Memory 错误。
4.4 Resource Group 监控
在进行监控时, QD 会把资源组查询 query 分发到各个 segment 上,然后再在 master 进行汇总,返回集群整体的资源利用情 况。
Greenplum 支持多种对资源组的监控方式,除了直接的资源组监控视图之外,还支持对 segment 、机器层级的资源组监控。这 些不同层级的资源组监控视图往往是通过对系统表和系统函数进行联合查询得到的,比如:
CREATE VIEW gp_toolkit.gp_resgroup_status AS
SELECT r.rsgname, s.*
FROM pg_resgroup_get_status(null) AS s,
pg_resgroup AS r
WHERE s.groupid = r.oid;
所以,我们介绍最基本的资源监控函数 pg_resgroup_get_status 的实现方式。
static void
getResUsage(ResGroupStatCtx *ctx, Oid inGroupId)
{
int64 *usages;
TimestampTz *timestamps;
int i, j;
usages = palloc(sizeof(*usages) * ctx->nGroups);
timestamps = palloc(sizeof(*timestamps) * ctx->nGroups);
for (j = 0; j < ctx->nGroups; j++)
{
ResGroupStat *row = &ctx->groups[j];
Oid groupId = DatumGetObjectId(row->groupId);
usages[j] = ResGroupOps_GetCpuUsage(groupId);
timestamps[j] = GetCurrentTimestamp();
}
if (Gp_role == GP_ROLE_DISPATCH)
{
CdbPgResults cdb_pgresults = {NULL, 0};
StringInfoData buffer;
initStringInfo(&buffer);
appendStringInfo(&buffer,
"SELECT groupid, cpu_usage, memory_usage "
"FROM pg_resgroup_get_status(%d)",
inGroupId);
CdbDispatchCommand(buffer.data, DF_WITH_SNAPSHOT, &cdb_pgresults);
if (cdb_pgresults.numResults == 0)
elog(ERROR, "pg_resgroup_get_status() didn't get back any resource statistic from the segDBs");
for (i = 0; i < cdb_pgresults.numResults; i++)
{
struct pg_result *pg_result = cdb_pgresults.pg_results[i];
/*
* Any error here should have propagated into errbuf, so we shouldn't
* ever see anything other that tuples_ok here. But, check to be
* sure.
*/
if (PQresultStatus(pg_result) != PGRES_TUPLES_OK)
{
cdbdisp_clearCdbPgResults(&cdb_pgresults);
elog(ERROR, "pg_resgroup_get_status(): resultStatus not tuples_Ok");
}
Assert(PQntuples(pg_result) == ctx->nGroups);
for (j = 0; j < ctx->nGroups; j++)
{
const char *result;
ResGroupStat *row = &ctx->groups[j];
Oid groupId = pg_atoi(PQgetvalue(pg_result, j, 0),
sizeof(Oid), 0);
Assert(groupId == row->groupId);
if (row->memUsage->len == 0)
{
Datum d = ResGroupGetStat(groupId, RES_GROUP_STAT_MEM_USAGE);
row->groupId = groupId;
appendStringInfo(row->memUsage, "{\"%d\":%s",
GpIdentity.segindex, DatumGetCString(d));
appendStringInfo(row->cpuUsage, "{");
calcCpuUsage(row->cpuUsage, usages[j], timestamps[j],
ResGroupOps_GetCpuUsage(groupId),
GetCurrentTimestamp());
}
result = PQgetvalue(pg_result, j, 1);
appendStringInfo(row->cpuUsage, ", %s", result);
result = PQgetvalue(pg_result, j, 2);
appendStringInfo(row->memUsage, ", %s", result);
if (i == cdb_pgresults.numResults - 1)
{
appendStringInfoChar(row->cpuUsage, '}');
appendStringInfoChar(row->memUsage, '}');
}
}
}
cdbdisp_clearCdbPgResults(&cdb_pgresults);
}
else
{
pg_usleep(300000);
for (j = 0; j < ctx->nGroups; j++)
{
ResGroupStat *row = &ctx->groups[j];
Oid groupId = DatumGetObjectId(row->groupId);
Datum d = ResGroupGetStat(groupId, RES_GROUP_STAT_MEM_USAGE);
appendStringInfo(row->memUsage, "\"%d\":%s",
GpIdentity.segindex, DatumGetCString(d));
calcCpuUsage(row->cpuUsage, usages[j], timestamps[j],
ResGroupOps_GetCpuUsage(groupId),
GetCurrentTimestamp());
}
}
}
结合这段代码我们看到, Master 节点( Gp_role = GP_ROLE_DISPATCH )在接收到查询资源状态的 SQL 之后,首先会将一个 相同的状态查询 SQL ( =SELECT groupid, cpu_usage, memory_usage FROM pg_resgroup_get_status ),分发给所有的
segment 节点。 Master 节点收到各个节点出来的结果之后,会进行排序汇总,然后返回最终结果。
而在各个节点真实计算的时候,对于内存消耗的计算,会返回实时统计的内存统计结果。
而对于 cpu 的计算,会在一开始先调用 ResGroupOps_GetCpuUsage 计算一次 cpu 使用量,通过读取磁盘上 cgroup 对应节点的 cpu 统计结果。然后 sleep 300000 us ,重新调用 ResGroupOps_GetCpuUsage 再计算一次 cpu 使用量,通过两次结果的差值返 回 cpu 的统计结果。
static void
calcCpuUsage(StringInfoData *str,
int64 usageBegin, TimestampTz timestampBegin,
int64 usageEnd, TimestampTz timestampEnd)
{
int64 duration;
long secs;
int usecs;
int64 usage;
usage = usageEnd - usageBegin;
TimestampDifference(timestampBegin, timestampEnd, &secs, &usecs);
duration = secs * 1000000 + usecs;
appendStringInfo(str, "\"%d\":%.2f",
GpIdentity.segindex,
ResGroupOps_ConvertCpuUsageToPercent(usage, duration));
}
5 常见问题
5.1 Resource Group 是如何利用操作系统的 cgroup 能力的?
答:对于每个资源组,数据库会在系统的 cgroup 路径下创建一个以资源组 oid 命名的子路径,即做对应的 cgroup 挂载。创建资源组或者修改资源组配置的时候,数据库会对应修改对应子节点的 cgroup 配置。实 际执行事务时,数据库会将对应进程的 pid 写入对应的 cgroup 路径下,从而纳入 cgroup 的限制中。
5.2 Resource Group 是如何进行事务级别的资源限制的?
答:数据库对于每个资源组,根据并发限制,将资源划分成多个 slot 。
对于每个事务,在开启事务 (startTransaction) 的时候, QD 都会尝试获取一个 slot 。如果获取不到就会 一直等待其他事务完成执行并释放 slot 。
5.3 Resource Group 的各种操作加不加锁,加什么锁?
资源组的创建和修改都会加 ResGroupLock 类型的 exclusive lock ,而 backend 获取 slot 来执行事务的时候也会获取 ResGroupLock 的 exclusive lock ,所以资源组相关的变更,会与对应资源组内的事务执行相互阻塞。另外, Resource Group 配置修改的时候,还会对相关系统表加 AccessExclusiveLock 。
5.4 数据库基于 cgroup 对资源组进行限制,如果某个数据库节点故障,跨机迁移到其他节点,而 cgroup 的配置和路径结构无法迁移,会不会导致对应机器上的 resource group 功能失效?
答:不会。在数据库节点初始化的时候 (initPostgres) ,会进行资源组的检测,如果系统表中的资源组 配置在 cgroup 路径中不存在,会重新创建对应的 cgroup 挂载。
同理,如果你配置好了 ResourceGroup 之后,直接把你机器上的对应 oid 的 cgroup 子路径删掉,重启下数 据库就会恢复正常的状态。
5.5 为什么资源组的 CPU 使用率高于配置的 CPU_RATE_LIMIT ?
答:资源组可能存在 CPU 抢占的情况:当其他资源组空闲时,忙碌的资源组可以使用比其 CPU_RATE_LIMIT 更多的 CPU 。在这种情况下,数据库将空闲资源组的 CPU 资源分配给更繁忙的资源组。
5.6 Resource Group 在部署上有什么要求?
答:
- 安装并开启 cgroup ;
- cgroup 做好初始化挂载,初始化配置举例:
group gpdb {
perm {
task {
uid = gpadmin;
gid = gpadmin;
}
admin {
uid = gpadmin;
gid = gpadmin;
}
}
cpu {
}
cpuacct {
}
cpuset {
}
memory {
}
}
实际使用时要根据自身情况(系统用户名)修改配置;
- cpu 和 cpuset 对应的路径必须分开挂载。
6 总结
资源管理对于数据库集群的多租户管理、资源细粒度分配具有很重要的价值。 Resource Group 巧妙地基 于操作系统的 cgroup 隔离能力和 PostgreSQL 本身的基于 MemoryContext 的内存管理能力,以很少的代码量 实现了完备的资源管理功能。在 GP5 之后, Resource Group 主键替代 Resource Queue 成为主流的资源管理 方式, Greenplum 社区也把 Resource Group 当做主要去维护和优化的资源管理方式。
对 Greenplum 内存管理感兴趣的话,可以参考一下文章:基于 MemoryContext 的内存管理
对另外一种资源管理方式感兴趣的话,可以参考下文章: Greenplum 资源管理—— Resource Queue 使用和实现分析