- 1 INTRODUCTION
- 2 RELATED WORK
- 3 SYSTEM ARCHITECTURE
- 3.1 ByteNDB Overview
- 3.2 System Overview
- 3.3 Metadata Service
- 3.4 OLAP Engine
- 4 SHARED STORAGE WITH HIGH DATA FRESHNESS
- 4.1 Delta Store
- 4.2 Base Store
- 4.3 High Data Freshness
- 5 LSN-BASED STRONG DATA CONSISTENCY
- 6 OLAP QUERY PERFORMANCE OPTIMIZATION
本文为摘录,原文为: ../pdf/5/p3411-chen.pdf
- ByteHTAP: an HTAP system with high data freshness and strong data consistency.
- 独立引擎和共享存储架构
1 INTRODUCTION
- 字节的实际需求:
- 对刚刚(sub-second, 亚秒级)导入的数据进行复杂分析
- 支持事务和强一致性
- Build HTAP with following Global Designs:
- 规模大 (Large Scale) 字节的应用,有亿级的用户,需要构建分布式、实时分析系统,可以支撑 PB 级数据
- 实时 (Real time)
- 高度新数据 Highly fresh data changes
- 数据强一致性
根据架构,可将 HTAP 分为两类: 1 单引擎系统
- 使用一个引擎,例如 SAP Hana 和 MemSQL 。
- 根据数据格式可以分成两类:
- 单一数据格式 或者
- 混合数据格式
2 独立引擎
- 使用不同的引擎来处理 AP 和 TP ,例如 WildFire 和 TiDB
- 根据存储结构可以分成:
- 独立存储
- 生产中使用较为广泛
- 数据不够“新鲜”
- 共享存储
- 独立存储
- 字节采用了 独立引擎 + 共享存储 :
独立引擎
- 开发一个能够处理 AP 和 TP 的单一引擎,工作量不小
- 开源的、能够很好的处理混合模型的引擎没几个
- 而处理单一模型的引擎则较多(开源或者闭源的)
- 采用独立引擎,各司其职:
- TP: ByteNDB
- AP: Apache Flink
共享存储
- 字节现有的基础系统采用存储计算分离模型
- ByteNDB 的架构类似于 Amazon Aurora
- 将 ByteNDB 的复制存储进行拓展,支持了列存,以便将变更以最小延迟在存储存传播
- 列存用于 OLAP
- 还做了一个内存中的 delta store, 用于保存最新的数据变更, 供 OLAP 使用
架构对用户透明
- 用户使用一套 SQL API 来进行 AP 和 TP 的查询
- 由代理 (proxy) 将 SQL 自动转发给 AP 或者 TP 引擎
- 模块化设计,将来可以方便的将 AP 引擎换成其他引擎
- 仅需要实现一个存储和新引擎之间的 connector
2 RELATED WORK
- SAP Hana
- MemSQL
- TiDB
- TiKV
- TiFlash
- WildFire
- Spark
- Wiser
3 SYSTEM ARCHITECTURE
3.1 ByteNDB Overview
ByteNDB 的总体架构如图 1 所示。

- 一写多读
- 改进了 MySQL 的缓存池, 事务和锁管理 (
所以 ByteNDB 是基于 MySQL 改的?)以支持 master-replica 同步 - Log Store: 存储 redo log
- Page Store: 应用 redo log, 形成真正数据
- 类似 Aurora: Log is Database!
- 两个 Store 都是构建在分布式存储之上
3.2 System Overview
ByteHTAP 的架构如图 2 所示:
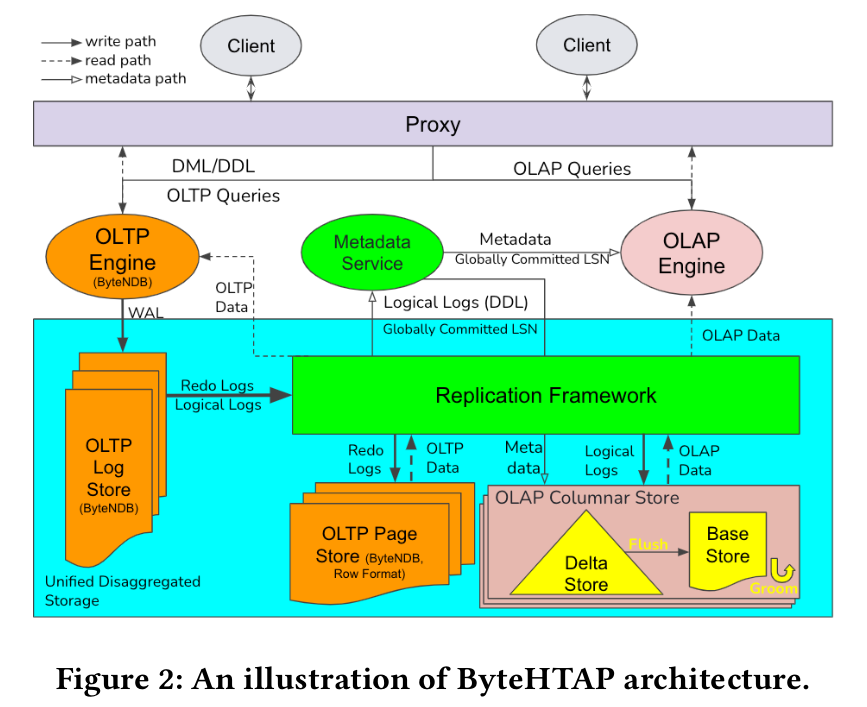
采用 独立引擎+共享存储
一套 API, 通过 proxy 自动分发给 OLTP 或者 OLAP 引擎
- OLTP \[\Longrightarrow\] ByteNDB
- OLAP \[\Longrightarrow\] Flink
Proxy 规则
- 交由 OLTP:
- DML, DDL, 简单查询
- 其他需要使用 TP 表的查询
- 交由 OLAP:
- 复杂查询 (join, aggr)
- 交由 OLTP:
每个表必须有一个主键:
- 列存要按照该建进行排序
- 主键值可以通过 DML 更改 (受 OLTP 引擎自动提供的约束限制)
用户可对对列存表指定分区列
- 当前仅支持哈希分区
数据一致性
- 每个 DML & DDL 都有一个唯一的 LSN
- 同一事务中的语句包装在一起
- 元数据服务向 OLAP 引擎提供全局已提交的 LSN
- 任何小于此 LSN 的 LSN 都应该已经被 OLAP 所接收并持久化
- OLAP 的查询会被赋予一个基于全局已提交 LSN 生成的只读 LSN 用于查询
- data changes 通常控制在 1 秒以内。
目前 不支持混合了 DML 与只读查询的事务 无分布式事务支持
3.3 Metadata Service
中心化的元数据服务 (Metadata Service MDS)
用于提供统一的服务,包括:
- catalog 系统表
- 仅供 AP 使用
- TP 自行存储
- 跨 AP 和 TP 的分区信息
- 供 AP 和 TP 所使用的数据统计信息
- 减少其他 ByteHTAP 模块的状态信息
- 提供全局已提交 LSN
- 用于 OLAP 查询作为只读 LSN 使用
- catalog 系统表
MDS 基于 Zookeeper 构建,支持高可用
MDS 的客户端
- 集成进了 OLAP 计算引擎以及存储服务 以便和 MDS 交互,获取多版本的元数据
- 集成进了 DDL 解析器
MDS 信息来源: DDL 逻辑日志:
- 由 OLTP 引擎生成,包含元数据变更信息
- 由复制框架中继传播给 TP 的 Page Store 和 AP 的 Column Store 以及 MDS
- MDS 对逻辑日志进行解析,由此产生系统表和分区 schema,并进行序列化和持久化,向外提供信息
3.4 OLAP Engine
使用 Apache Flink 作为 AP 的计算引擎
- 评估过 Spark, Flink, Presto
- TPC-H 和 TPC-DS 性能相近
- 选用 Flink:
- 公司内使用广泛
- 支持流式查询 (Streaming Queries)
- Flink 结合列存,形成计算引擎
Data Connector
- 用于高效、并行读取列存数据
- 支持聚集和扫描下推
- 支持分区修正 (partition prune),过滤掉不需要的分区
4 SHARED STORAGE WITH HIGH DATA FRESHNESS
- 共享存储: Delta Store + Base Store
Delta Store
- 保存在内存中
- 行模式
- 及时应用日志(低延迟)生成新鲜数据供 OLAP 使用
Base Store
- 以列存形式持久化保存
复制框架 Replication Framework
- 管理 Delta Store, Base Store 和 Log Store, Page Store
4.1 Delta Store
高可用:
- 分区: OLAP 表会进行分区
- 副本: 每个分区有三个副本
- Delta Store: 每个分区的每个副本一个 Delta Store
Delta Store 包含两个列表, 以逻辑日志中的 LSN 为序
- Insertion List
- 记录插入操作
- Deletion List
- 记录删除操作
- Delete Hash Map
- SCAN 操作需要访问 base store 和 delta store 来检查某一行是否已经删除
- 从 Deletion List 构建 Delete Hash Map, 用于加速查询
- Insertion List
Delta Store 有四种主要的操作,且可以并行:
- 日志应用 LogApply
- Flush 从 Delta Store 生成 Base Store
- Garbage Collection
- Scan
4.2 Base Store
持久化列存
- 每个分片的每个副本创建一个
Base Store 中不保存 LSN
- 优点
- 减少存储负担
- 提升 scan 和 update 的效率
- 缺点
- 只能读取 Delta Store 中保存的快照
- 更老的快照无法获取
- 优点
Base Store 的数据
保存格式为 Partitioned Attributes Across (PAX)
每个 Base Store 包含多个数据块 (data blocks)
- 每个数据块默认大为 32MB, 由若干行组成
- 数据块内部按照主键排序
- 内部既保存了:
块级的元数据
- 行数
- key range
- 主键构建的 BloomFilter (XXX: 这个可以考虑)
- 每列的统计信息:如 min/max
每一列编码后的数据 (encoded data for each column)
仅支持 value based index
Groom
Why?
- 数据删除操作,仅更新 bitmap, 而不删除数据
- 长期操作会导致磁盘使用空间不断增长
- Flush 操作产生的分区表的范围可能重叠
- scan 操作需要访问多个分区,性能差
数据合并
- 后台线程运行
- 周期性检查:
- 已删除的数据占比
- 不同数据块主键重叠
- 将符合上述特征的数据块进行合并
- 新块将不包含已删除数据
- 最小化重叠的主键
- 合并后
- 更新 metadata
- 将原 block 添加到 GC list
垃圾回收
- 后台运行
- 定期检查 GC list
- 如果没有 active session 在访问,则删除之
4.3 High Data Freshness
5 LSN-BASED STRONG DATA CONSISTENCY
6 OLAP QUERY PERFORMANCE OPTIMIZATION
6.1 Delete Optimization for Scans
6.2 Computation Pushdown to Storage Engine
Predicate Pushdown
- min/max 块级过滤
- 减少无用 IO
- 延迟物化
- 优先计算条件列
- 再去读取其他列
- 减少 IO
- min/max 块级过滤
Aggregate Pushdown
- 每个分片上先做部分聚集 (Partial Aggregate)
- 最后汇总二次聚集
6.3 OLAP Query Engine Optimization
对 Flink 的改进,包括:
- 统计信息收集
- 异步读取
- 并行优化