- 1 Abort HashData
- 2 设计理念
- 3 架构介绍
- 4 产品特性
本文为摘录,原文为: https://docs.hashdata.xyz/docs/20-product-guide/
1 Abort HashData
HashData was founded in 2016 by the guys who built Apache HAWQ, one of the most advanced SQL on Hadoop solutions. As the flagship product of the company, HashData Warehousing is a data warehouse service built for the cloud. While 100% compatible with the analytics interfaces of the open source MPP database Greenplum,HashData’s unique architecture delivers proven breakthroughs in performance, concurrency, elasticity and simplicity.
HashData 成立于 2016 年,由构建 Apache HAWQ 的团队创立,后者是最先进的 SQL on Hadoop 解决方案之 一。作为公司的旗舰产品,HashData Warehousing 是一种为云构建的数据仓库服务。虽然与开源 MPP 数据库 Greenplum 的分析接口 100%兼容,但 HashData 的独特架构在性能、并发性、弹性和简单性方面 取得了明显突破。
2 设计理念
HashData 云数仓是专 为云原生基础架构平台设计研发的分析性数据库 。 其核心设计理念是通过重构数据库处理核心,充分适配云原生基础架构,发挥云基础设施的资源弹 性、运维管理和利用效率优势。这大幅提高了数据库服务在云原生架构下的配置效率,实现了 计 算和存储的弹性扩展以及按需分配 的优势,从而为客户带来超高的投入产出比。
HashData 云数仓具有 近乎无限可扩展的数据容量、并发性和分析性能 。 它能够帮助企业整合内部的数据孤岛,轻松共享受监管的数据,并执行各种数据分析负载。同时, 它能够无缝地跨越多个公共云和私有云,提供一致的数据分析体验。作为企业数据分析的核心引擎, HashData 为数据仓库、数据湖、数据工程、数据科学、数据应用程序开发和数据共享提供整体的 解决方案。
HashData 的愿景是 让加载数据、分析数据、挖掘价值等任务变得更简单 :
- 打造一个让更多人能够更轻松地挖掘数据价值的平台,
- 消除企业规划、购买和运维基础设施带来的负担,
- 让企业专注于核心业务。
3 架构介绍
HashData 云数仓的技术架构如下图所示:

HashData 的云数仓分为管理模块和用户模块两大模块。其中:
- 管理模块包括管理控制台
- 用户模块包括租户集群,包含元数据服务、计算集服务和数据存储服务。
3.1 管理模块
管理模块是云数仓的关键组成部分,用于管理控制平台(Cloudmanager)。其主要职责是 管理元数据 集群和计算集群 ,包括创建、启停、资源管理以及监控告警等功能。
作为云数仓的重要组件,管理控制台能够统一管理各类云平台资源,并整合数据库集群的监控、运维 和管理功能,建立统一的数字化管理和运维平台。通过实现图形化和自动化操作,管理模块实现了 “所见即所得”的效果,大大降低了数据仓库集群的运维管理成本,使企业用户能够高效便捷地管理上 万节点的数据仓库集群。
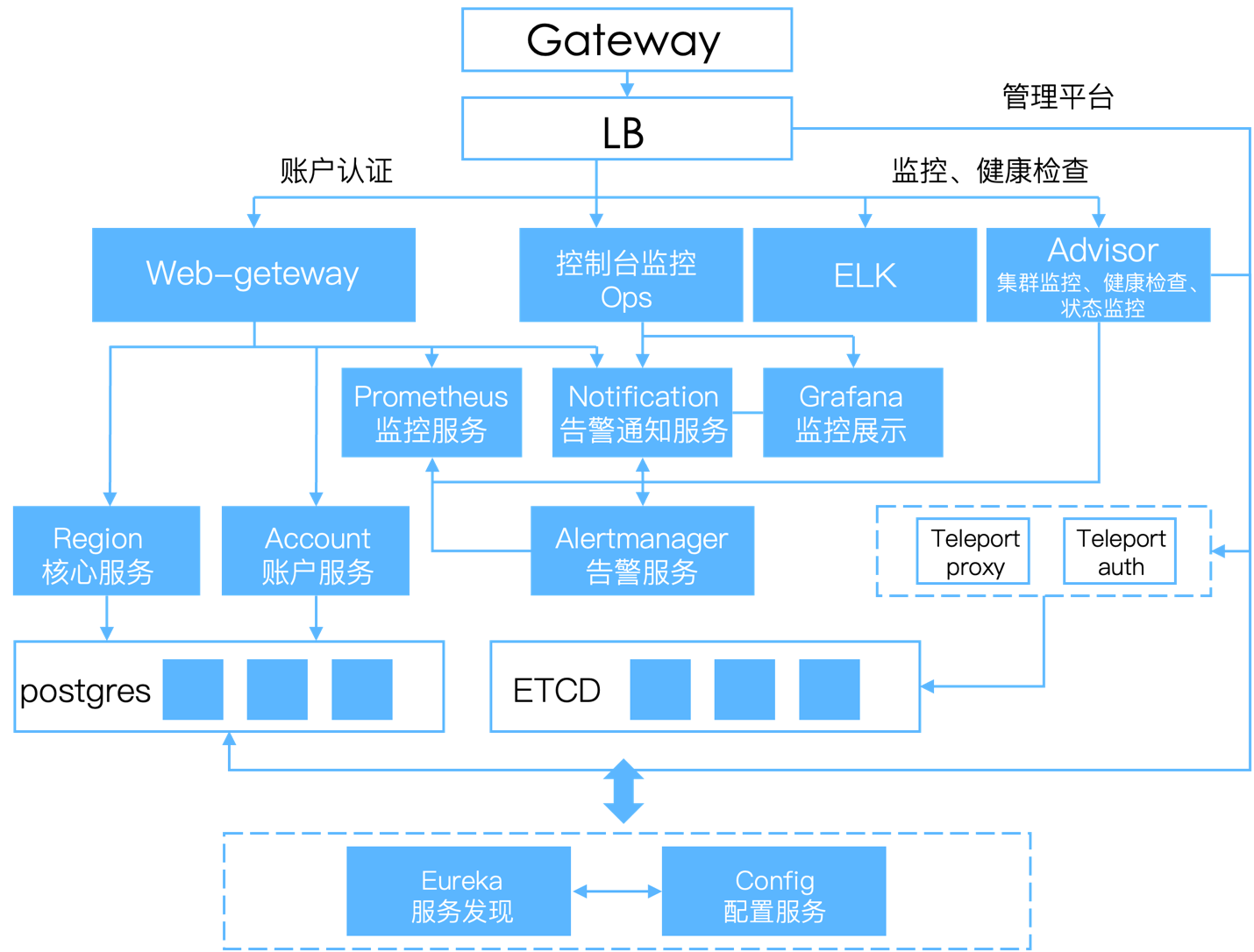
用户可以在管理控制台中进行:
- 创建/删除、启动/停止、扩容/缩容、升级集群等操作;
- 管理底层的对象存储、基础设施(节点生命周期等);
- 查询和管理数据仓库自身的元数据,如用户、数据库、表、锁等;
- 配置管理 ETL 任务,编辑、保存 SQL 文本等。
3.2 用户模块
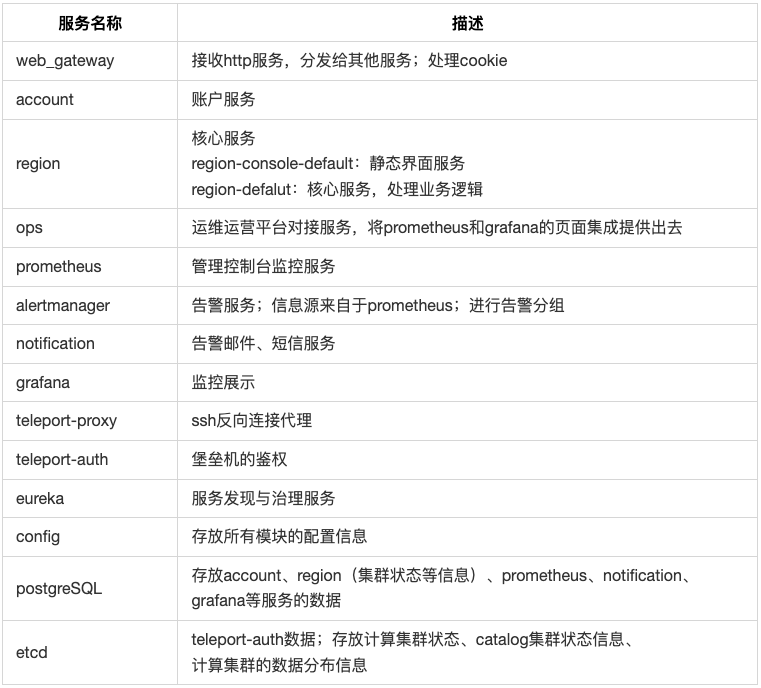
HashData 云数仓的用户模块主要分为三个层次:元数据服务层、计算层和数据存储层。这三个层次 之间是完全解耦的。
元数据服务层负责管理整个集群的元数据和事务,保证数据的一致性和完整性。
计算层主要负责接收用户查询请求、协调查询、优化查询和执行计算任务。
数据存储层提供持久化数据服务,所有计算集群节点都可以访问数据存储层,确保数据的可靠性 和高可用性。
3.2.1 元数据服务层
元数据服务层包括:调度层、服务层、元数据持久层,架构和各层功能如下:
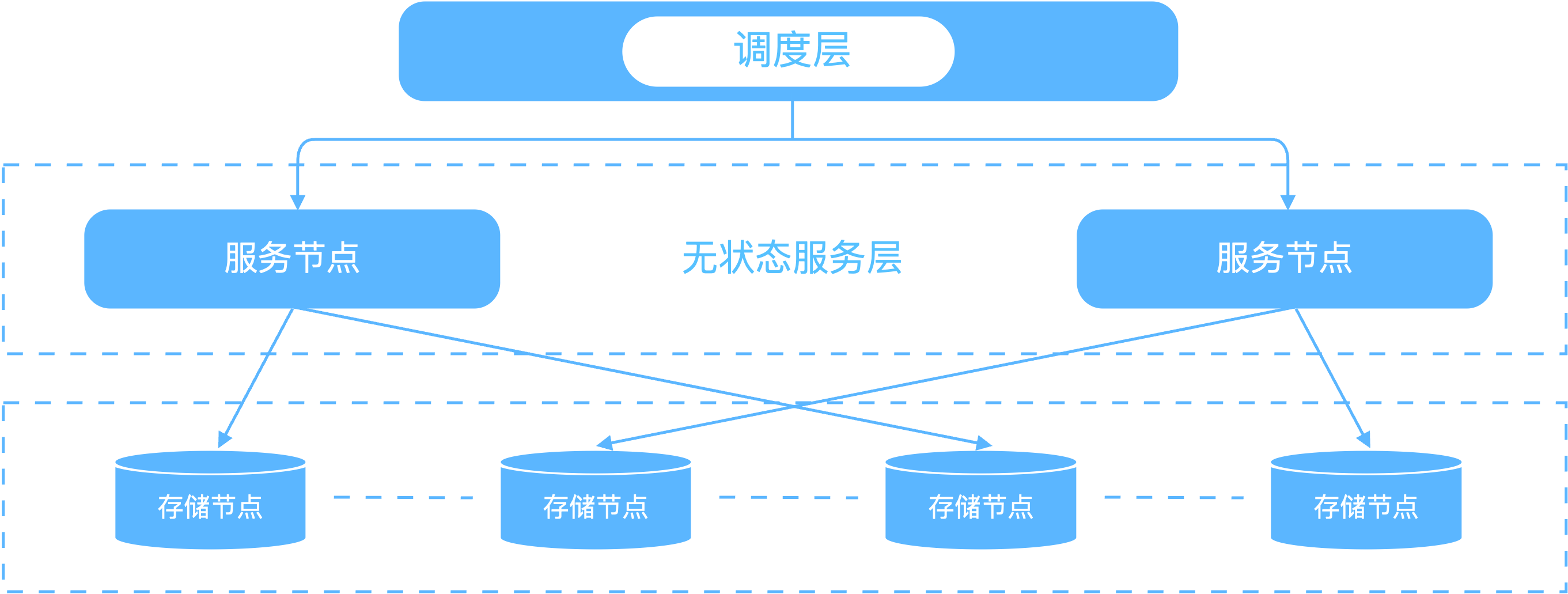
调度层
- 提供服务发现:
- 新建计算集群后,由调度层分配服务节点与计算集群的主节点进行连接,进行后续的元数据访 问;
- 如果计算集群与服务节点的连接断开,需要重新建立连接时,由调度层决定该计算集群应该访 问哪个服务节点;
- 调度层能够监控服务层和计算层的服务状态,当有节点宕机、服务进程宕或不可用等情况下,调度层将信息反馈给管理组件;
- 提供负载均衡:
- 调度层集群中的每个节点都存有等量数据,客户端连接时将自动进行节点分配,保证节点负载 均衡(多活架构);
- 调度层作为计算层与元数据层之间的桥梁,统筹协调对主节点与服务层之间的连接,保证连接 的负载均衡;
- 提供服务发现:
服务层
- 服务层由一组服务节点组成,
- 每个服务节点其实是无状态的服务进程
- 负责接收计算集群发送过来的元数据请求。
元数据持久层
- 提供元数据存储服务;
- 提供元数据多副本及高可用服务。
3.2.1.1 元数据服务层的部署架构
元数据服务层是计算集群与数据库元数据交互的入口,而调度层主要用于服务发现,采用默认的 etcd 集群配置以保证高可用性。服务节点是无状态的进程,可以在任意空闲的物理服务器上启动。 元数据持久层通过 FoundationDB 实现。
在系统中,调度层决定每个计算集群应该访问哪个元数据服务节点,
- 所有系统持久化状态信息都保存在元数据存储层中。
- 元数据服务层用于缓存热点元数据信息在内存中,并维护一些临时状态。
当元数据服务节点失败时,保存在内存的信息会丢失,但不会影响系统信息的一致性。系统会启动一 个全新的元数据服务节点来替换失败的节点,并重新加载需要的状态信息。系统通过调度层实现元数 据的负载均衡。
3.2.1.2 元数据服务的高可用机制
该架构遵循物理上解耦、逻辑上集成的原则。
整个元数据服务分为三层:
调度层、 调度层采用 etcd 集群来保证高可用性,
元数据服务层 元数据服务层无状态,因此即使节点失败,只需启动一个新的节点即可恢复;
- 元数据持久层 元数据持久层采用 FoundationDB 集群来保证高可用性。
整个元数据服务的高可用性取决于每个层级本身的高可用性。管理组件负责监控每一层的节点故障, 并在保证各层高可用性的前提下将新的空闲节点替换失败的节点,以确保处理能力不下降。每一层根 据需要提供的安全系数来调整部署方式和规模。
整体而言,该架构设计思想以高可用性、分布式数据库技术和根据需要调整规模为核心,确保 元数据服务的稳定运行和可靠性。
3.2.2 计算层
计算层会包含多个独立的计算集群,这些集群共享存储服务和元数据服务,可以从共享服务中加载和 查询数据,每个集群的资源和操作都是独立的,从而实现高度的敏捷性。
每个计算集群包含两种逻辑角色:主节点(Master)和计算节点(Segment),并由一个主节点和多 个计算节点组成。
在这个逻辑结构中:
主节点负责管理和协调计算集群的操作
- 充当 QD 角色:
- 负责接受用户连接
- 进行认证授权
- SQL 解析,
- 生成查询计划,
- 分发查询计划给计算节点,
- 汇总查询结构并返回给用户
- 主节点的本地磁盘只用做元数据的缓存使用:
- 所有元数据都存放在元数据持久层
- 所有的元数据请求及持久化操作都需要与元数据服务进行交互
- 充当 QD 角色:
计算节点则执行具体的计算任务。
充当 QE 的角色,是及集群中的计算单元
- 根据主节点分发的执行计划进行 SQL 运算
- 将执行结果反馈给主节点
计算节点不做应用数据持久化存储
- 根据需求从对象存储缓存所需数据
用户可以选择在物理服务器、虚拟服务器或容器上部署层,可以通过管理控制台配置每个物理服务器 的 Segment 实例数量、操作系统参数和数据库参数。用户可以根据需求启动、暂停或扩容集群,新 提交的查询会自动在调整后的新集群运行。在同一个共享存储的不同计算集群上可以独立运行不同的 任务,实现基于同一份数据的并行大吞吐量工作负载,满足用户对低延迟和快速响应的需求。此外, 它还支持在批量加载数据的表上进行数据科学操作,并为用户的仪表盘提供亚秒级的响应时间。最后, 由于存在多个集群,可以在不停机或者对性能无影响的情况下,对单个集群进行扩缩容操作,提供了 真正的弹性,计算节点数可以在 2 个和 1024 个之间任意伸缩。
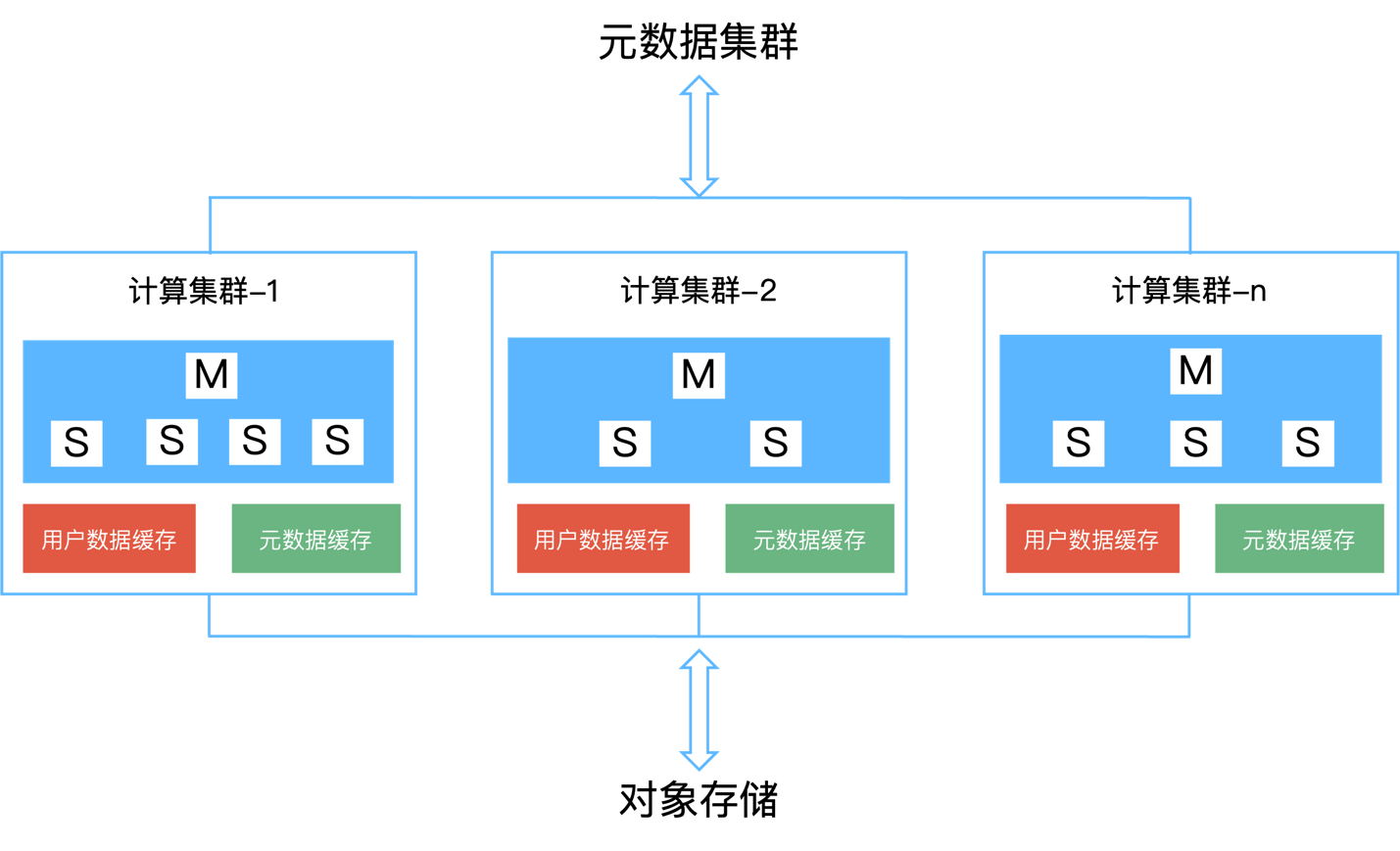
3.2.2.1 数据分布式算法
HashData 云数仓采用的 基于一致性哈希算法 的数据分布策略, 其基本原理如下图所示:
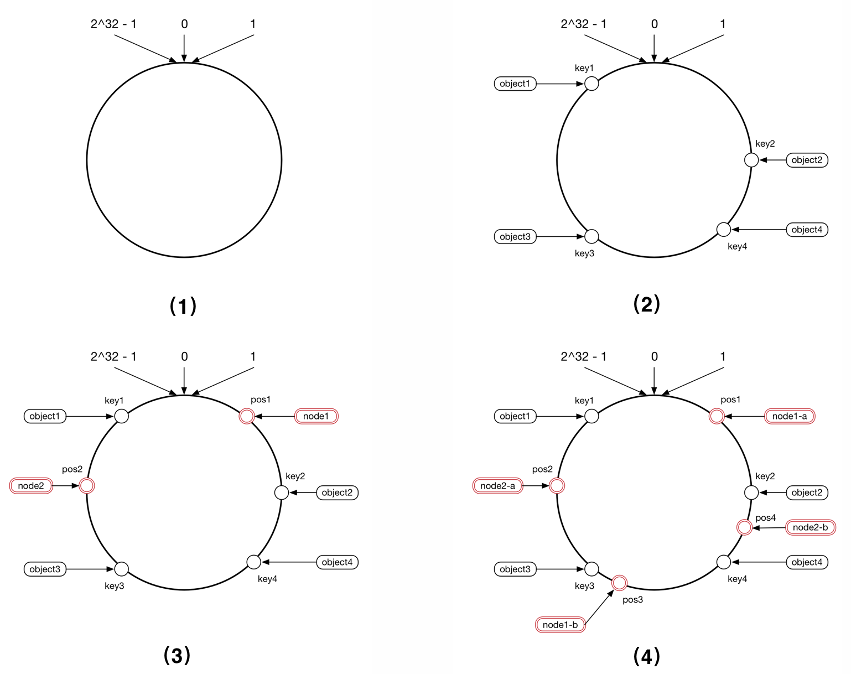
一致性哈希算法通过将每条记录的内容计算出 Hash 值,然后映射到一个环上的一点,再将环分成若 干连续的区间,每个区间对应一个计算节点,从而实现数据分布。新增节点时只需转移少量数据,是 其最大优点。
与传统 MPP 架构的数据库相比,尽管一些产品采用了一致性哈希的数据分布策略,但在经典的完全 无共享架构下,增删节点仍需迁移部分数据,虽然数据量减少。但 HashData 云数仓采用共享存储架 构,在增加节点后,数据无需迁移,新的查询可实现秒级扩容。
在上图所示的例子中 (3,4),开始的时候集群包含两个计算节点,并将数据分成了六个切片。节点 1 负责 数据切片 1、2、3,节点 2 负责数据切片 4、5、6。增加一个新的节点 3 之后,数据并不需要发生 任何迁移。节点添加完成后,新的查询执行的时候,节点 1 负责数据切片 1、2,节点 2 负责数据 切片 4、5,新增的节点 3 负责数据切片 3、6,但数据切片 3、6 不需要从节点 1、2 的缓存中抓 取,而是直接从对象存储访问,然后在节点 3 本地缓存,从而做到秒级扩容。
3.2.2.2 计算集群高可用
该段文字主要描述了在计算集群中一台物理机发生故障后,管理组件能够感知并执行不同的故障恢复 策略,
- 替换发生故障的物理节点
- 选择一个空闲的物理节点加入到计算集群,替换发生故障的物理节点
- 由于计算节点是没有状态的,整个替换过程非常迅速
- 当计算节点失败时,在底层的 IaaS 资源是充足的情况下,系统会通过底层的 IaaS 提供的 API 按照提前做好的镜像启动一个新的虚拟机,替换发生故障的计算节点。
- 从而确保一个计算节点发生故障的时候,系统能够及时启动新的虚拟机接替故障节点。而虚拟机 所在的物理机发生故障的情况,IaaS 层会自动处理,上层的 HashData 云数仓是无感知的。
- 剔除发生故障的物理节点
- 当没有空闲的物理节点的情况下,计算集群执行一个类似缩容的操作将发生故障的物理节点踢出可用计算节点列表中,
- 这样新来的查询就按照新的可用计算节点列表来生成查询计划。
- 在生成查询计划的过程中,每个计算节点负责的数据块(包括后续的计算分析)将会按照一致性 哈希的策略重新计算,等价于原来由发生故障节点负责的任务均匀打散分配给其它剩余正常工作 的计算节点。
- 在节点发生故障后会导致每个计算节点负责的数据块(包括后续的计算分析)按照一致性哈希的 策略重新映射(哪个正常工作的节点负责哪个数据块)的过程完全是按需的,只针对当前准备要 执行的 SQL 语句,而不是全量的数据。所以每台物理服务器本地的磁盘容量大小对发生故障后 恢复的效率没有任何影响。
- 后续发生故障的节点恢复了,只需要执行一个扩容的操作就可以将修复后的计算节点加入到可用计算节点列表中,这样新的查询就可以用上这个添加回来的节点。
3.2.2.3 计算集群数据缓存
对象存储服务理论上提供了无限的存储空间,但性能低于云盘或物理硬盘。为了提高计算集群的效率, HashData 云数仓使用本地硬盘作为对象存储服务的缓存,存储热点数据,减少直接访问对象存储的 延迟和 API 调用开销,从而提升整体 IO 性能。该数据缓存方案跨集群、跨数据中心以及跨云中心 实现数据访问,并保证数据的强一致性,用户可灵活合理地规划数据部署和使用。
通常情况下,缓存占热数据的 50% 左右和全量数据的 5%~10% 左右,系统性能将接近完全使用本地 盘的水平。本地缓存的容量取决于本地磁盘的容量。
本地缓存主要有两种级别的策略:
- 最底层的是经典的 LRU 算法,在缓存空间不足时,会踢掉老数据;
- 上层的策略是根据数据库当前执行的 SQL 语句操作决定。
- 比如,ANALYZE 语句需要访问的数据不会被缓存,因为其只是为了更新统计信息,并不知道下次 访问这张表的数据是何时。
- INSERT INTO SELECT FROM 这类语句访问到的数据也不会被缓存,因为后续访问的数据通常是 INTO 的目标表,而不是 FROM 的源表。
- 通过估算热点数据来确定本地缓存系统的大小,以实现更高的查询性能。
3.2.3 数据存储层
数据存储层采用对象存储实现,提供统一的用户数据持久化,并以其架构优势实现数据访问安全和高 可用功能。HashData 采用标准的对象存储访问协议,可与各类对象存储产品对接。

HashData 云数据仓库是基于对象存储和抽象服务构建的,支持多种对象存储方式。
在公有云场景下,对象存储与云虚拟块存储服务有显著差别:对象存储根据实际使用量按需收费, 且单位容量的存储成本远低于类似 EBS 的云盘。这种按需付费和低存储成本让基于对象存储的云端 数据仓库使用成本大幅降低。
在私有云环境中,对象存储集群的单位建设成本远低于块存储集群,对服务器和磁盘的要求也较低。 此外,对象存储集群自身支持纠删码机制,比 Hadoop 集群的多副本节省更多存储空间。另外, HashData 云数据仓库还支持独有的压缩算法,进一步提升了存储空间利用率。
4 产品特性
4.1 数据仓库服务
HashData 云数仓提供了企业用户快速启动数据仓库集群的能力,加载数据后可以立即进行数据分析 任务。该数据库还承担了集群资源配置、数据备份、监控审计、错误恢复、高可用和升级等繁杂的运 维工作,让用户专注于业务分析。
4.2 灵活高效的业务支持
这段文字主要讲述了共享存储的优势,它可以让不同的计算集群独立运行不同的任务,实现基于同一 份数据的并行运行大吞吐量工作负载。这样可以满足用户对低延迟、快速响应的需求。另外,用户还 可以在批量加载数据的表上进行数据科学操作,并为用户仪表盘提供亚秒级的数据支持。
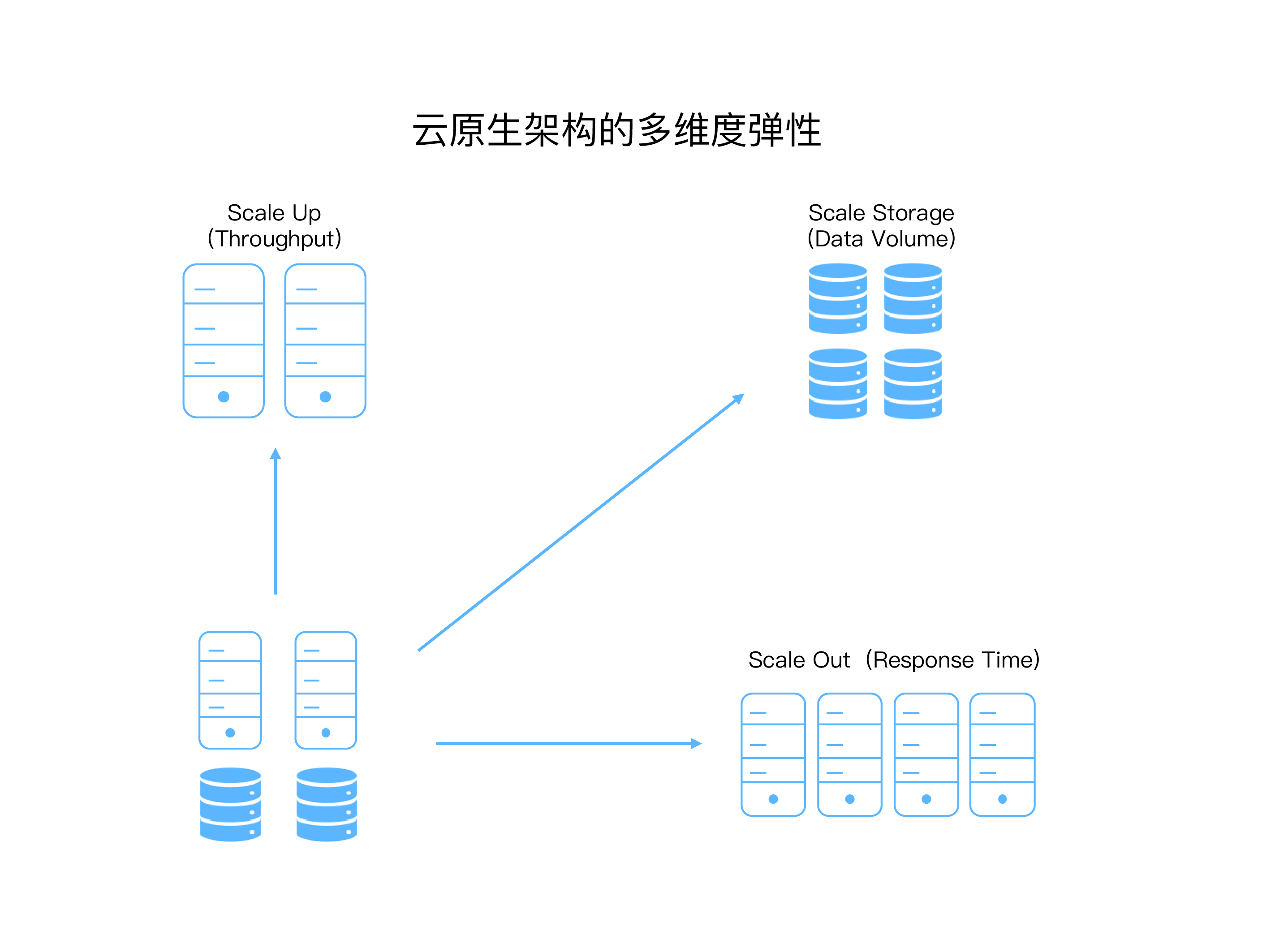
4.3 多维度弹性
HashData 云数仓支持独立的扩展计算和存储,可以根据需求灵活增减吞吐量。
- 云原生架构可通过扩展存储应对不断增长的数据量,
- 增加计算集群数量以适应用户增加,
- 还可增加计算节点以提高响应速度,实现吞吐量、数据容量和响应时间的完全弹性。
4.4 高可用和低成本
HashData 云数仓的整体架构设计思想包括物理上解耦、逻辑上集成,以及实现无单点故障设计。该 架构涵盖管理控制台、元数据服务层、计算层和数据存储层,所有功能组件均实现了无单点故障和自 动故障恢复,确保整个数据库服务能够实现高可用和高容错。云数仓可以部署在主流公有云和私有云 环境,无论部署方式如何,都可实现故障自愈的高可用,并支持按需关闭或挂起暂时不用的数据库以 控制成本。
4.5 接近零停机时间
HashData 云数仓采用共享数据存储的架构设计,利用一致性 Hash 分布方案,能够实现在新建计算 集群、对单个集群进行扩容或缩容操作时,无需进行数据迁移,避免集群维护操作需要停机,用户可 以在此期间正常使用数据库。
4.6 优化的硬件配置
HashData 云数仓提供灵活的计算和存储资源配置,可以根据业务需求选择合适的资源配置。这意味 着可以利用小型计算集群处理 PB 级数据,也可以在较小的数据集上运行强大的计算集群。这种灵活 性能更好地满足不同业务类型的数据处理需求,同时大幅提高了硬件资源利用效率。
4.7 兼容开源
HashData 云数仓提供了与开源 PostgreSQL 和 Greenplum 完全兼容的查询接口和数据文件存储格式, 并且支持相同的访问协议。这使得用户可以充分利用已有的 SQL 技能和在 BI 和 ETL 工具方面的投 入,降低业务迁移成本。这种兼容性能够帮助用户轻松地迁移其现有的业务数据到 HashData 云数仓 平台中,而无需担心数据格式或查询接口的变化。
4.8 完善的数据库能力
该系统完全支持 UTF-8、GBK 等编码格式,支持多租户管理,关系数据模型和标准 SQL 语法。它还 支持行、列两种存储引擎,并且支持单表和多表并发的插入、更新、删除操作,以及行级锁。此外, 该系统满足事务数据强一致性,支持表数据并发增删改,支持主流的数据类型,以及常用数据库对象 的创建、修改和删除操作,包括数据库、表、索引、视图、存储过程和自定义函数。它还支持数据库 用户的创建、删除操作,以及用户权限的分配与回收。最后,该系统还支持完善的分区管理功能,以 及主流的 JDBC、ODBC 等接口。