PostgreSQL and NUMA
本文为摘录(或转载),侵删,原文为: -https://postgr.es/p/7kL -https://docs.redhat.com/en/documentation/red_hat_enterprise_linux/8/html/managing_monitoring_and_updating_the_kernel/assembly_configuring-cpu-affinity-and-numa-policies-using-systemd_managing-monitoring-and-updating-the-kernel#proc_configuring-numa-using-systemd_assembly_configuring-cpu-affinity-and-numa-policies-using-systemd -https://postgr.es/p/7ka
这一系列文章涵盖了在多处理器的大型系统上运行 PostgreSQL 的具体细节。我的经验是,当人们面临这个问题时,通常需要花费数月的时间来学习基本知识。这一系列文章旨在通过提供清晰的背景知识来消除这些困难。希望未来一代的数据库工程师和管理员不必通过反复试验花费数月的时间来弄明白这些问题。
本期文章专注于非均匀内存访问(NUMA)的低级“如何”和“为什么”,以便能够理解后续的解决方案和建议,重点关注概念细节。不幸的是,在许多细节上,这需要关注技术细节,因为通常没有细节的概念充其量是令人困惑的。
后续文章将基于本文中的信息。我们建议先阅读此文,然后根据需要进行回顾。
1 What is NUMA and why do we need it?
1.1 Historical Background
直到 1990 年代初,处理器系统,包括大型机,使用一种称为统一内存访问(Uniform Memory Access,UMA)的内存架构,在这种架构中,所有处理器通过统一的内存控制器访问主内存。通过锁定和其他措施,可以实现访问的并行化。随着处理器和内存控制器的改进,在大型机之外并行化内存访问的能力变得愈加重要。
内存管理带来了许多挑战。大多数访问必须是串行的,因为在写入进行时不能进行读取,同时在并发读取内存时可能会面临技术或电子限制。因此,我们必须确保每个内存块在读取和写入时都是串行访问的,同时又要确保在内存系统的不同部分可以同时进行多次不同的读取和写入操作。
大型机通过一个复杂的内存管理层解决了这个问题,其中包括一个用于锁的高速内存区域,但在大型机之外,这种方法并未被视为可行,因此非均匀内存访问(NUMA)应运而生。
NUMA 的理念是,我们可以放弃访问所有内存具有相似延迟的保证,从而实现架构,使得每组处理器能够访问某些比其他内存更快的内存。这一定义是一个实用的权衡,但并没有告诉您 NUMA 如何工作、我们为什么需要它以及如何管理它。这个权衡的理由在于,它允许我们在内存控制器之间划分内存,内存控制器现在可以保证对它所控制的内存进行串行访问。这个关键细节对于理解硬件层面的 NUMA 及其软件层面至关重要。
1.2 How NUMA works
传统的统一内存访问(UMA)对称多处理服务器(每个插槽 2 个内核,2 个插槽)中,每个核心通过外部内存控制器访问内存,如下所示:
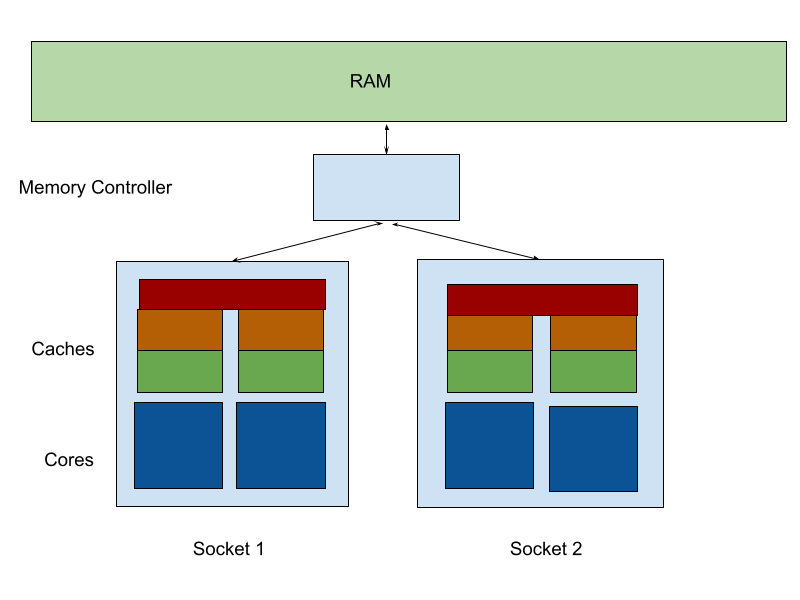
在这里,我们看到每对核心共享一个 L3 缓存,并且它们通过一个共享的内存控制器请求 RAM,该控制器可以访问系统上所有的内存。
随着核心数量的增加,这种架构会出现瓶颈。大型机通过基于锁定内存区域和高速共享锁缓存的架构解决了这些问题。然而,如果我们接受内存的本地/远程划分,那么并行性将变得更加容易。
因此,我们将系统内存分成多个区域,并将这些区域分配给内存控制器。一个每个插槽 4 个核心的 2 插槽系统,且每个插槽有一个内存控制器,可能看起来是这样的:
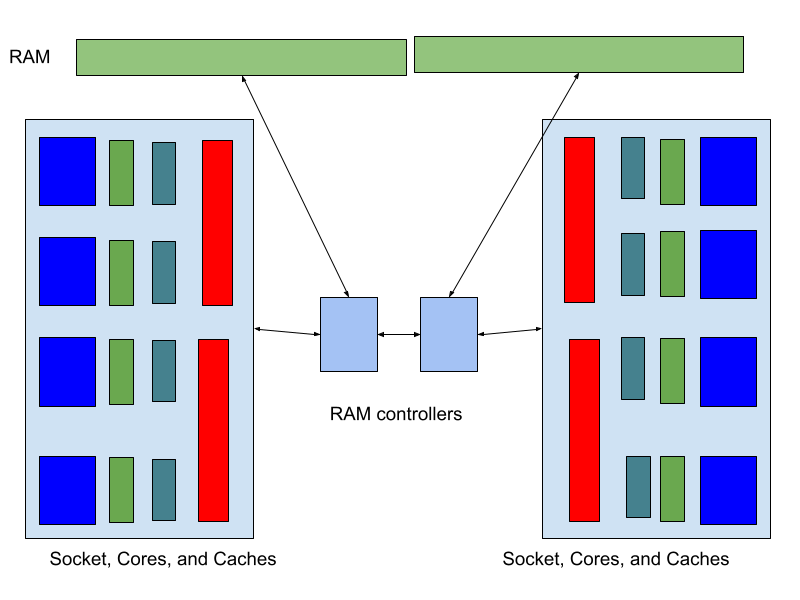
现在,每个核心可以访问整个系统中的 RAM,但仅有部分内存可以被直接访问。如果内存是非本地的,那么一个内存控制器会向另一个内存控制器请求访问,而数据则通过高速互连在不同 NUMA 节点之间传输。如果进程在处理器之间移动,它们的指令和工作内存也必须通过这个总线进行传输,可能是通过页面迁移(见下文)或间接访问。
当然,每个插槽可以有多个内存控制器,如下方的主板所示。

在这里,您可以看到每个插槽有两组内存银行。CPU 可以进一步将每个内存银行划分为多个区域。
1.3 Linux and NUMA
1.3.1 Allocation Policies 分配策略
Linux 内核提供了多种内存分配策略(包括新线程和进程的可执行内存),管理员可以使用 numactl 程序为特定进程进行调优,systemd 也支持在单元文件中设置 NUMA 策略。
该机制的一个重要限制是,这些策略会影响分配和线程启动,因此可能产生次优的交互。例如,在交错进程下启动的线程或进程,其自己的分配也会交错,因此至少会有部分内存被分配到其他 NUMA 节点。另一方面,如果所有设置为本地,则内存和线程只会在一个 NUMA 域中启动,从而导致内存被换出、交换到磁盘,并可能在远程 NUMA 节点中被换入。
主要策略包括:
local本地(默认):- 如果可能,优先使用当前节点。
- 如果不可能,则在其他节点上分配。
membind内存绑定:- 仅在当前节点上分配。
- 如果空间不足,则分配失败。
interleave交错:
以轮询方式在所有指定节点上分配。- 这意味着当一个进程请求分配时,内存将会在所有可用节点上进行分配。
- 这也意味着每个具有这种策略的进程至少会有一部分内存在互联总线中分配,尽管进程和页面的迁移可能会随时间发生变化。
1.3.1.1 27.1. Configuring CPU affinity using systemd
CPU 亲和性设置有助于限制特定进程对某些 CPU 的访问。实际上,CPU 调度程序不会在不在该进程亲和性掩码中的 CPU 上调度该进程运行。
默认的 CPU 亲和性掩码适用于所有由 systemd 管理的服务。
要为特定的 systemd 服务配置 CPU 亲和性掩码,systemd 提供了 CPUAffinity= 选项,既可以在单元文件中使用,也可以在
/etc/systemd/system.conf 文件中的管理器配置选项中设置。
CPUAffinity= 单元文件选项设置一个 CPU 列表或 CPU 范围,这些会合并并作为亲和性掩码使用。而
/etc/systemd/system.conf 文件中的 CPUAffinity 选项则定义了进程标识号(PID)为 1
的进程及其派生的所有进程的亲和性掩码。你可以在每个服务的基础上覆盖该 CPUAffinity 设置。
To set CPU affinity mask for a particular systemd service using the CPUAffinity unit file option:
Check the values of the CPUAffinity unit file option in the service of your choice:
1systemctl show --property <CPU affinity configuration option> <service name>As a root, set the required value of the CPUAffinity unit file option for the CPU ranges used as the affinity mask:
1systemctl set-property <service name> CPUAffinity=<value>Restart the service to apply the changes.
1systemctl restart <service name>
To set CPU affinity mask for a particular systemd service using the manager configuration option:
- Edit the /etc/systemd/system.conf file:
1vi /etc/systemd/system.conf - Search for the CPUAffinity= option and set the CPU numbers
- Save the edited file and restart the server to apply the changes.
1.3.1.2 Configuring NUMA policies using systemd
非一致性内存访问(NUMA)是一种计算机内存子系统设计,其中内存访问时间取决于物理内存位置与处理器的相对距离。
靠近 CPU 的内存具有更低的延迟(本地内存),而对于不同 CPU 的本地内存(外部内存)或在一组 CPU 之间共享的内存则具有更高的延迟。
在 Linux 内核中,NUMA 策略决定了内核为进程分配物理内存页面的位置(例如,在哪些 NUMA 节点上)。
systemd 提供了单元文件选项 NUMAPolicy 和 NUMAMask 来控制服务的内存分配策略。
步骤
要通过 NUMAPolicy 单元文件选项设置 NUMA 内存策略:
检查所选服务的 NUMAPolicy 单元文件选项的值:
1systemctl show --property <NUMA policy configuration option> <service name>以 root 用户身份设置 NUMAPolicy 单元文件选项所需的策略类型:
1systemctl set-property <service name> NUMAPolicy=<value>重启服务以应用更改:
1systemctl restart <service name>
要使用 [Manager] 配置选项设置全局 NUMAPolicy 设置:
在
/etc/systemd/system.conf文件中搜索 [Manager] 部分中的 NUMAPolicy 选项。编辑策略类型并保存文件。
重新加载 systemd 配置:
1systemctl daemon-reload重启服务器。
重要提示
当配置严格的 NUMA 策略时,例如绑定(bind),确保也适当地设置 CPUAffinity= 单元文件选项。
1.3.1.3 NUMA policy configuration options for systemd
systemd 提供以下选项来配置 NUMA 策略:
NUMAPolicy
控制执行进程的 NUMA 内存策略。可以使用以下策略类型:
- default(默认)
- preferred(首选)
- bind(绑定)
- interleave(交错)
- local(本地)
NUMAMask
控制与所选 NUMA 策略相关联的 NUMA 节点列表。
请注意,对于以下策略,你不必指定 NUMAMask 选项:
- default(默认)
- local(本地)
对于首选策略,列表仅指定一个 NUMA 节点。
1.3.2 Page and Process Migration
分配策略仅提供一个起始点。调度器可以根据需要将进程和页面移动到连接到其他内存控制器的 CPU 内核。这意味着随着时间的推移,调度器将尝试根据使用情况将内存和进程进行合并。
Linux 内核扫描内存访问模式,并定期决定将数据页面从一个 CPU 集合(和 NUMA 节点)迁移到另一个。这一过程也很复杂,但涉及到将页面固定(锁定)后再移动到内存的另一部分。
还有第二种迁移类型,调度器可能会安排将进程移动到更接近其需要访问的内存的节点。在这种情况下,一个进程及其部分或全部本地内存将被移动到同一互联网络上的另一个 NUMA 域。
1.4 Conclusions
NUMA 在现代具有大量核心和大容量内存的服务器中带来了许多挑战。Linux 内核中的基本 NUMA 控制并不够细粒度,无法使所有操作都以最佳性能运作,尤其是在应用程序未直接管理其自己的 NUMA 策略的情况下。然而,理解这些基础知识为管理在大型系统上运行的软件提供了基础。
理解这些机制是必要的,以便理解权衡。这在本系列后续条目中将变得很重要。
本系列的下一篇文章将讨论在以 Linux 为操作系统的 NUMA 系统上运行 Postgres 17 及更低版本的情况。这些建议在一定程度上也适用于 18 版本,即使它支持 libnuma。
2 NUMA, Linux, and PostgreSQL before libnuma Support
2.1 PostgreSQL, NUMA, Linux, and Huge Pages
在大多数架构上,Linux 的默认内存页大小为 4 KB。这意味着这些页可以按该大小进行换页到磁盘,并且可以根据该大小单独迁移到其他 NUMA 节点。内部每个页面(无论是大页还是小页)都有一个条目存储在一个名为翻译后备缓冲区(Translation Lookaside Buffer,TLB)的缓冲区中,该缓冲区负责处理内存分配的逻辑地址到物理地址的映射。
PostgreSQL 可以使用大页(huge pages)来配置共享内存,其中最常见的大页大小为 2MB。这在 NUMA 系统上有许多重要影响,下面将详细探讨。然而,一个关键点是,使用普通页面时,通常需要两个 Linux 页面才能构成一个 Postgres 的缓冲页面,而使用大页时,256 个缓冲页面可以适配到一个单独的 Linux 大页中。
上述内容假设 PostgreSQL 使用标准的 8KB 页面大小,但相同的基本动态也适用于其他页面大小。
这意味着,由于在访问单位中有一对页面,因此它们很可能会一起迁移(这会加倍迁移页面的开销,并显著增加决策迁移内容时的开销)。另一方面,将多个缓冲页面存储在一个操作系统页面中意味着这些页面更有可能不会被迁移,因此会受到远程访问的惩罚。
- Huge Pages & Transparent Huge Pages (THP)
大页(Huge Pages)不应与透明大页(Transparent Huge Pages)混淆,后者是一个内核特性,能够在未直接请求时使用大页。由于在某些工作负载和内核版本上有报告称会产生负面性能影响,因此一般不建议使用透明大页。
2.2 How PostgreSQL’s Architecture Intersects with NUMA
PostgreSQL 采用多进程架构,服务器上的每个连接由一个后端进程处理,同时还有许多其他特殊进程执行其他相关任务,包括:
- 后台写入器(background writer),负责将脏页面刷写到磁盘
- 检查点进程(checkpointer),确保所有脏页面都被刷写,并在 WAL 中设置检查点
- 负责复制的各种进程
- 各种维护任务,比如清理(vacuum)和分析(analyze)
- 针对特定任务的自定义后端(例如在 pg_cron 或 pg_partman 中)
每个进程都会分配自己的内存,并且这些进程组也会连接到共享内存,所有进程都必须能够访问该共享内存。
2.2.1 Why the Checkpointer is Often a Bottleneck
检查点进程(checkpointer)负责确保在系统崩溃后能够通过从最后一个检查点回放预写日志(write-ahead log,WAL)来恢复数据。它通过将脏缓冲区从共享内存刷写到磁盘,并发出 fsync 命令以确保持久性来完成这一任务。虽然操作系统缓存并不是问题,但检查点进程确实需要遍历所有共享内存,这可能会根据是否与检查点进程位于同一位置而导致额外开销。
在 NUMA 系统中,一个典型的问题是检查点进程的 CPU 使用率达到 100%,而其他进程则处于限制状态。在这种情况下,检查点进程很可能在大多数时间内都在访问跨互连的内存(可能是与其他 CPU 插槽相连的内存),因此大部分时间都在等待内存。通常,这个问题可以通过使用大页来解决。
2.2.2 How Huge Pages Affect Checkpointer Performance
如上所述,当不使用大页时,每个缓冲页面会跨越多个操作系统页面(默认情况下是两个)。这意味着每次对缓冲页面的查找在内部通常需要进行两次操作系统页面的查找。在这种配置下,迁移进程或页面的机会有限,因此,一个关键的瓶颈是在内存控制器之间访问页面时可能会面临的延迟。
然而,使用大页时,一系列相邻的缓冲页面会在同一分配中。这使得操作系统能够将页面迁移到离检查点进程更近的地方,或者更有可能的是将检查点进程迁移到离正在访问的页面更近的位置。
结果是,该瓶颈进程能够优先获得更快的访问速度,而查询后端进程则更可能需要通过互连访问页面。这消除了一个瓶颈,并提高了系统的速度。
2.3 How NUMA Policies affect PostgreSQL
Linux 的 NUMA 策略影响线程创建和内存分配。这在 NUMA 系统上可能会产生一些意想不到的结果。
2.3.1 The membind policy
当使用 membind 时,Postmaster 及其所有子进程将启动在指定的 NUMA 节点上,并且它们的所有内存分配也将保存在该节点。如果使用了文件缓存,这些缓存可能会存储在其他地方。
Membind 实际上意味着不将工作分散到其他核心或内存段。这在 PostgreSQL 是系统上唯一的进程且不希望使用其他核心时是可以接受的。
它的优点是在小型系统上优化性能,同时牺牲了可扩展性。在这种情况下,所有内存访问都是快速的,但性能受到限制,仅限于与指定内存控制器连接的核心和 RAM 的集合,以及该内存控制器本身的吞吐量。
2.3.2 The prefer policy
在 prefer 策略下,Postmaster、共享内存以及尽可能多的进程将启动在指定的 NUMA 节点上,但内存或进程可能会溢出到其他 NUMA 节点。这基本上类似于上述的 membind 策略,但在 NUMA 节点耗尽时,性能会更加平滑地下降。
该策略是 Linux 的默认设置,也是为什么在 NUMA 系统上运行 PostgreSQL 时,用户的典型体验往往不佳的原因之一。人们期望更大的服务器能够解决性能问题,但如果系统仍然主要局限于单个 NUMA 节点,那么这通常不会产生实质性的差异。
2.3.3 The interleave policy
在“交错”(interleave)策略下,所有分配和所有进程都通过轮询的方式分散到所有指定的 NUMA 节点。关键在于,这种做法使得共享内存中的页面得以分散。由于普通的 Linux 页面足够小,以至于缓冲页面跨越多个 Linux 页面,这意味着一个单独的缓冲页面最初会分布在多个 NUMA 节点上,从而确保所有缓冲访问至少部分是远程的。虽然随着时间的推移可能会迁移页面以避免这种情况,但并不能保证。大页的使用会显著改变这一布局,从而使访问能够本地化。
交错策略的第二个重要方面是后端的本地分配也会在 NUMA 节点之间分散。随着时间的推移,被重复使用的内存会与后端进程共同存在,但这种情况并不适用于临时分配,例如用于连接操作的哈希表。
幸运的是,PostgreSQL 在内存重用方面经过了良好的优化,因此用于处理输入行的 8 KB 缓冲区会被有效地重复使用。尽管如此,这仍然意味着交错策略整体上优先考虑了内存吞吐量和共享内存的分配,而在连接操作性能方面则不太理想。
2.4 Recommendations
幸运的是,在 NUMA 系统上运行 PostgreSQL 时,无需关注 NUMA 的建议相对较少:
- 将
huge_pages设置为开启, - 并通过 systemd 或 numactl 使用交错(
interleave)NUMA 策略。
2.4.1 Enable Huge Pages
在所有版本的 PostgreSQL 中,无论是否支持 NUMA,都应配置 PostgreSQL 使用大页,并应预先分配足够的大页以覆盖所有共享内存。这适用于 PostgreSQL 在 NUMA 系统上运行的任何情况,只要不使用 membind 策略。在所有其他情况下,大页对于允许检查点进程的内存共置至关重要。
有关设置大页的更多信息,包括计算所需数量、在操作系统中设置等,可以参考 Umair Shahid 的博客文章《为 PostgreSQL 配置 Linux 大页》。
2.4.2 Use the interleave policy
在我们在具有大量核心的服务器上运行 PostgreSQL 时,大多数情况下我们希望 PostgreSQL 能够使用它所需的任何内存,并希望 PostgreSQL 能够有效利用所有核心。这可以通过交错(interleave)策略来最佳实现。
然而,这项建议对使用 libnuma 支持构建的 PostgreSQL 18 并没有影响。