Velox: Meta’s Unified Execution Engine
- 1 ABSTRACT
- 2 INTRODUCTION
- 3 LIBRARY OVERVIEW
- 4 USE CASES
- 5 DEEP DIVE
- 5.1 TODO Type System
- 5.2 Vectors
- 5.3 Expression Eval
- 5.4 Functions
- 5.5 Operators
- 5.6 Memory Management
本文为摘录(或转载),侵删,原文为: attachments/pdf/8/p3372-pedreira.pdf
1 ABSTRACT
Velox:
C++ database acceleration library
用来:
- 构建执行引擎
- 应对复杂数据类型
- 增强数据管理系统 (enhance data management system)
- 构建执行引擎
倚赖:
- 向量化 (vectorization)
- 自适应 (adaptivity)
Meta 内部已经或正在将其与其他组件集成,包括:
- 分析型查询引擎
- Presto
- Spark
- 流处理平台
- 消息总线
- 数据仓库
- 机器学习
- PyTorch
- 分析型查询引擎
2 INTRODUCTION
仅做计算,无 SQL 解析、优化器等,其价值:
- 效率
- 一致性
- 工程效率
3 LIBRARY OVERVIEW
是什么
- 开源 C++ 数据库加速库
- 可用来加速、扩展和增强数据的计算引擎:
- 高性能计算
- 可重用
- 可扩展
不是什么
- 无语法前端
- SQL 解析
- 全局优化等
- 无语法前端
也就意味着:
- Velox 的输入是 已经优化好的执行计划
- 将执行计划在本地执行
- Velox 的组件

4 USE CASES
5 DEEP DIVE
TODO 5.1 Type System
TypeSystem 用于表示各种数据类型:
原生类型
- 整形
- 不同精度的浮点数类型
- 字符串
- varchar
- varbinary
- 日期
- 时间戳
- 函数 (lambda 表达式)
复杂类型
- 数组
- 固定长度的数组
- maps
- rows, structs
上述类型可以嵌套,并序列化、反序列化
- 还可以包装 C++ 的结构体
支持类型扩展:
- Find How????
5.2 Vectors
- Vectors 用来表示列式数据
- 列式、编码后的数据
- 用作组件之间的输入和输出
- 扩展自 Apache Arrow 格式,扩展包括
- size (行数)
- type
- null bitmap
- 可嵌套
Velox Buffers
- 从内存池中分配出的连续空间
- Vector 保存在 Velox buffers 中
引用计数
- Buffer 和 Vector 都有引用计数
- 一个 buffer 可以被多个 Vector 引用
- 只有引用计数为 1 的数据是可变的
- shared vector 和 buffer 可通用 copy-on-write 技术变成可写
5.2.1 Arrow Comparison
5.3 Expression Eval
表达式计算引擎,可用作
- 过滤投影算子 – 用于过滤和投影表达式
- TableScan 和 IO connectors: 过滤条件下推
- 用作单独的计算组件:计算表达式
使用 Expression Tree 用作输入
- 树的每个节点可能是
- input column
- 常量
- 函数调用,由函数名和一系列的参数(表达式)构成
- CAST 表达式:用于类型转换?
- lambda 函数
- 树的每个节点可能是
函数计算分成两个部分: 编译和执行
5.3.1 Compilation
将输入的表达式树转换成为可执行的表达式,若干运行时优化技术:
- Common Subexpression Elimination
- Constant Folding
- Adaptive Conjunct Reordering
5.3.2 Evaluation.
5.4 Functions
5.4.1 Scalar Functions.
标量函数是从单行中获取值作为参数并生成单行输出的函数。
作为一个向量化引擎,Velox 的标量函数 API 同样是向量化的,它提供以向量(按批次)形式的输入参数,连同它们的可空性缓冲区以及描述活动行集合的位图。在许多情况下,向量化的标量函数可以利用列式数据布局以常数时间产生结果。例如,
𝑖𝑠_𝑛𝑢𝑙𝑙()函数可以通过直接返回内部可空性缓冲区来以常数时间实现;𝑐𝑎𝑟𝑑𝑖𝑛𝑎𝑙𝑖𝑡𝑦()函数可以利用表示向量中每个数组大小的内部长度缓冲区;𝑚𝑎𝑝_𝑘𝑒𝑦𝑠()/𝑚𝑎𝑝_𝑣𝑎𝑙𝑢𝑒𝑠()则可以返回输入 MapVector 的键或值的内部缓冲区。
然而,对于无法利用列式格式的其余函数,要求开发人员手动遍历每个输入行,正确处理可空性缓冲区、不同的输入(和输出)编码格式、复杂的嵌套类型,以及分配或重用输出缓冲区,变得过于繁琐(且容易出错),尤其考虑到实施这些函数的开发人员人数不断增长。此外,由于现代工作负载需求的多样性,例如高级字符串和 JSON 处理、日期和时间转换、数组/映射/结构的操作、正则表达式、数据科学的数学函数等,标量函数迅速占据了 Velox 代码库的最大部分。
5.4.1.1 Simple Function
考虑到上述开发人员生产力(和可靠性)问题,Velox 还提供了一个简单的标量函数 API,旨在追求简洁、易用,并尽可能隐藏底层引擎和数据布局的细节,同时仍然提供与向量化函数相同的性能水平。简单的标量函数 API 允许开发人员通过提供一个 C++函数来表达他们的业务逻辑,该函数一次处理一行值(而不是完整的向量),例如:
| |
5.4.1.2 Advanced String Processing.
5.4.1.2.1 Ascii ONLY
大多数字符串操作函数需要正确处理 UTF-8 字符,当输入仅由 ASCII 字符组成时,会造成不必要的开销。为了解决这个问题, 简单函数框架允许开发人员提供 𝑐𝑎𝑙𝑙() 函数的特殊版本 𝑐𝑎𝑙𝑙𝐴𝑠𝑐𝑖𝑖() ,当字符串输入为 ASCII-only 时,该版本会被自动调用。这个功能基于这样的观察:Meta 的数据仓库表中绝大多数字符串仅由 ASCII 字符组成。此外,简单函数还可以声明它们的 ASCII
行为,即如果所有字符串输入都是 ASCII-only,评估引擎是否可以假设由该函数生成的字符串输出也是 ASCII-only。该标志允许表达式评估引擎在这些函数生成的数据上跳过 ASCII 检测程序。图 1 比较了在 ASCII-only
输入上使用和不使用该优化时常见字符串操作函数的结果。
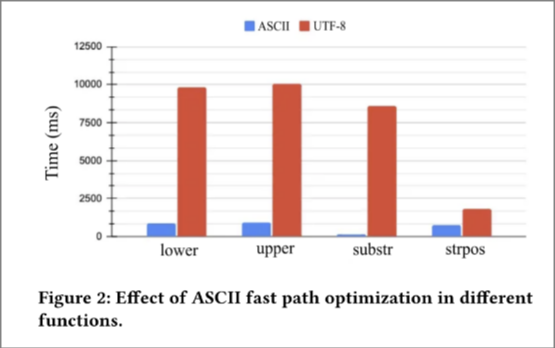
Figure 1: asicc-only-optimization
5.4.1.2.2 Inplace Oprations
许多字符串操作,例如 𝑠𝑢𝑏𝑠𝑡𝑟() 、 𝑡𝑟𝑖𝑚() 以及其他字符串分词函数,可以通过引用输入字符串在生成的输出字符串中实现零复制结果。为了实现这一点,函数开发人员需要在函数类中设置一个标志,通知引擎在生成的输出字符串向量上携带对特定输入字符串缓冲区的引用。该功能同样适用于生成字符串数组的函数,例如 𝑠𝑝𝑙𝑖𝑡() 。
2 展示了微基准测试,比较了三种不同实现的𝑠𝑢𝑏𝑠𝑡𝑟():不对输入编码做任何假设且不重用缓冲区(NoOpts), ASCII-only,以及 ASCII-only 且重用缓冲区的实现。
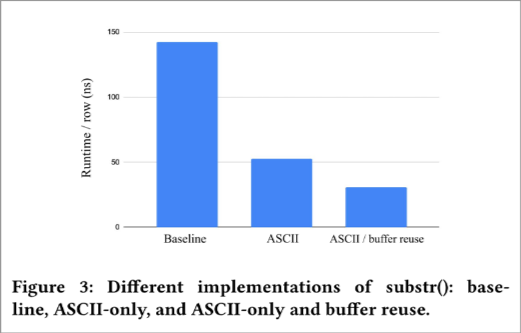
Figure 2: string functions
5.4.2 Aggregate Functions
聚合函数是将特定组中的多行数据汇总为单行输出的函数。在 Velox 中,聚合函数通常分为两个步骤进行计算:
- (a)部分聚合处理原始输入数据并生成中间结果,
- (b)最终聚合处理中间结果并产生最终结果。
Velox 还允许开发人员指定两个额外步骤:
- (c)单一聚合,用于数据已经按照分组键进行分区的情况,因此无需洗牌或中间结果,以及
- (d)中间聚合,用于合并部分聚合的结果,例如当多个线程并行计算以减少发送到最终聚合阶段的数据量时。
聚合函数可以根据其中间结果(也称为累加器)的特性分为固定大小和可变大小。
- 像
𝑐𝑜𝑢𝑛𝑡()、𝑠𝑢𝑚()、𝑎𝑣𝑔()、𝑚𝑖𝑛()和𝑚𝑎𝑥()这些函数使用固定大小的累加器, - 而像
𝑑𝑖𝑠𝑡𝑖𝑛𝑐𝑡()、𝑝𝑐𝑡()及其近似版本则需要可变大小的累加器。
考虑到在聚合过程中,数据以行存储,其中每一行对应一个单独的组或分组键值的唯一组合,固定大小的累加器内嵌存储在行内,而可变大小的累加器则存储在一个单独的缓冲区中,并在行中存储一个指针。关于哈希自适应性和哈希表布局的更多细节将在 4.5.2 小节中讨论。
5.5 Operators
Velox 计划由 PlanNodes 组成,执行时候,计划树被翻译成为执行树 (ExecTree)。多数情况下,计划节点到执行节点 (执行器) 是一一对应的,只有少数例外,如:
- Filter + Project ==> FilterProjector
- HashJoin ==> HashBuild + HashProbe
最顶层的 Velox 执行概念是任务(Task),它是分布式执行中功能传递的单位,对应于查询计划片段及其运算符树。任务以表扫描(TableScan)或交换(Exchange,洗牌)源作为输入开始,并以另一个交换作为结束。任务的运算符树被分解为一个或多个称为管道(Pipelines)的线性子树:例如,HashProbe 和 HashBuild 分别映射到一个管道。每个管道有一个或多个执行线程,称为驱动程序(Drivers),每个驱动程序都有其自己的状态。驱动程序可以在线程上运行或不运行,具体取决于它们是否有工作要执行。驱动程序可能因多种原因离开线程,例如,其消费者尚未消耗数据,源交换尚未产生数据,或扫描正在等待扫描文件。与传统的火山迭代器树模型相比,这种模型在进出线程时更加便利,因为状态可以恢复,而无需在栈上构建控制流。
最后,任务可以随时被其他 Velox 参与者取消或暂停。在强制优先级、检查点状态、迫使其他任务溢出或其他协调活动的情况下,能够暂停任务是非常方便的。
所有运算符都实现了相同的基本 API,包括诸如添加一批向量作为输入、获取一批向量作为输出、检查运算符是否准备好接受更多输入数据,以及通知不再添加更多数据等方法;后者可以用来通知阻塞排序或聚合以刷新其内部状态并开始生成输出。尽管 Velox 已经提供了一整套常用的运算符,但该库也允许引擎开发人员添加包含特定于引擎的业务逻辑的自定义运算符,例如用于流处理的基于流的聚合。一些常见运算符的重要特性和优化将在接下来的小节中描述。
5.5.1 Table Scans, Filter, and Project
表扫描是按列逐个进行,并支持过滤下推。
包含过滤器的列会首先被处理,生成命中行号以及可选的命中值。过滤器在运行时根据适应性进行排序,以确保优先评估在最短时间内能够丢弃值的过滤器。评分的定义为 时间 / (1 + 输入值 - 输出值) ,使得最佳过滤器在最短时间内丢弃最多的值。这与在 AND/OR 表达式中重新排序合取子句的原则相同,如第 4.3 节所述。
简单过滤器使用 SIMD 一次评估多个值,从而使 Velox 能够利用 AVX2 每个 CPU 时钟周期大致处理一个整数命中。字典编码数据的过滤结果会被缓存(如第 4.3 节所述),而 SIMD 再次用于通过
聚合 + 比较 + 掩码查找 + 重新排列 来检查缓存命中,从而平均在每个 CPU 时钟周期内处理多个命中并输出符合条件的行。Velox 还提供了针对大 IN
过滤器的高效实现,用于哈希连接下推,允许同时触发 4 次缓存未命中。
此外,FilterProject 运算符为所有的过滤和投影表达式使用一个单一的表达式评估上下文。对于每一批输入数据,运算符首先在所有输入行上评估过滤表达式,仅在通过过滤的行子集上执行投影表达式。如果没有行通过过滤,则完全跳过投影表达式的评估。
5.5.2 Aggregate and Hash Joins.
哈希连接和聚合是分析数据处理的核心。Velox 提供了一种经过精心设计的哈希表实现,针对这两种用例进行了优化,这不仅促进了可重用性,还统一了两种场景下的自适应性。
哈希键以列式的方式处理,使用一种称为 VectorHasher 的抽象,该抽象识别键的范围和基数,并在适用时将键转换为较小的整数域。
- 如果所有键都映射到少数几个整数,它们将直接映射到一个扁平数组。
- 如果存在多个键,它们会尽可能映射为单一的 64 位规范化键,然后根据生成键的范围被用作扁平数组的索引或作为单个哈希表键。
只有在上述优化都不适用的情况下,才会使用低效的多部分哈希键。
此外,最佳的哈希布局是自适应决定的,并会随着新数据批次的处理而变化。考虑到 VectorHashers 形成每个键的独特值摘要,这些对象也可以下推到表扫描中,并在表扫描和哈希连接共同存在的情况下用作高效的 IN 过滤器。
哈希表的布局类似于 Meta 的 F14。不同键的查找之间的内存访问是交错的,旨在最大限度地提高同时进行的缓存未命中的数量,并减少因数据依赖导致的管道停顿。哈希表的值以逐行存储的方式存放,以最小化 cache miss.